 |
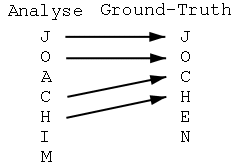
Jochen Schäfer
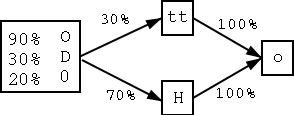
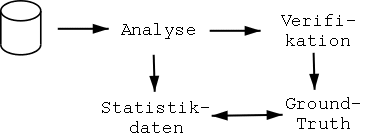
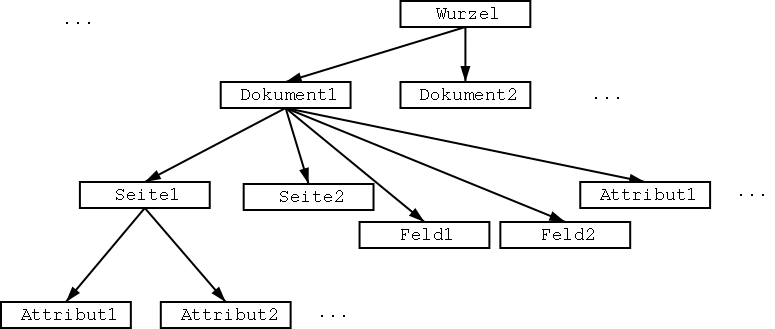
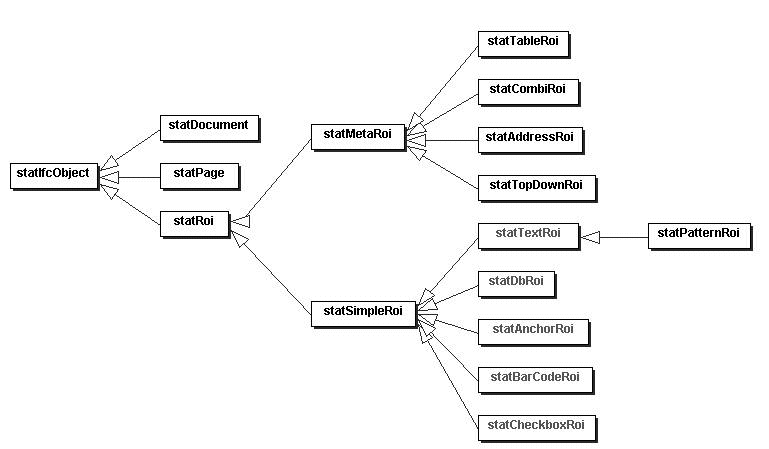
Dokument.ClassID=Document Dokument.Name=Dokument Dokument.isGT=1Mehrfachnennungen eines Attributs sind erlaubt und können als Liste gelesen werden. Wird das Attribut jedoch als einzelner Wert eingelesen, wird als Wert das letzte Vorkommen des Attributs zurückgegeben. Das Format ist zwar unabhängig vom Vorhandensein bestimmter Attribute oder Werte eines Objektes, jedoch können Änderungen der Semantik von Attributen nicht durch das Programm abgefangen werden. Dazu muss jeweils ein Konvertierungsprogramm erstellt werden, dass ältere Daten in die gewünschte Form bringt. Eine andere Möglichkeit wäre es das Analyseprogramm so zu ändern, dass es die Formate erkennt und entsprechend reagiert.
|
|
| Name | Typ |
| statDocumentPtr | daPointer<statDocument> |
| statPagePtr | daPointer<statPage> |
| statRoiPtr | daPointer<statRoi> |
| statTableRoiPtr | daPointer<statTableRoi> |
| statPageList | list<daPointer<statPage> > |
| statRoiList | list<daPointer<statRoi> > |
| ideeStringList | list<ideeString> |
| ideeStringVec | vector<ideeString> |
| ideeStringField | vector<vector<ideeString> > |
| statStreamFunc | statAsciiDb& (*func)(statAsciiDb&) |
| statManipFunc | statAsciiDb& (*func)(statAsciiDb&, const ideeString&) |
| ideeStringPairList | list<pair<ideeString, ideeString> > |
| statNode | ideeTreeNode<statNodeObj> |
| Name | Datentyp | Beschreibung | Zugriff |
| Name | ideeString | Enthält den Namen des Objekts. | rw |
| IsGround | bool | Ist IsGround true, dann ist dieses Objekt Ground-Truth. Ansonsten ist das Objekt ein Vergleichsobjekt. | rw |
| Name | Beschreibung |
| statIfcObject() | Der Standardkonstruktor |
| statIfcObject(const ifcObject &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Pages | statPageList | Die Liste der Seiten, die in diesem Dokument enthalten sind. | r |
| RoiList | statRoiList | Die Liste der Felder, die in diesem Dokument enthalten sind. | r |
| DocClass | ideeString | Die Dokumentenklasse dieses Dokuments. | rw |
| Name | Beschreibung |
| statDocument() | Der Standardkonstruktor |
| statDocument(const statDocument &obj) | Der Copy-Konstruktor |
| void addPage(const statPagePtr &page) | Fügt eine neue Seite zu diesem Dokument hinzu. |
| const statPagePtr& page(const ideeString &name) | Sucht eine Seite mit dem Namen name und gibt die gefundene Seite zurück. Wurde kein entsprechendes Feld gefunden, so gibt die Methode einen NULL-Zeiger zurück. |
| void addRoi(const statRoiPtr &roi) | Fügt ein neues Feld zu diesem Dokument hinzu. |
| const statRoiPtr& roi(const ideeString &name) | Sucht ein Feld mit dem Namen name und gibt das gefundene Feld zurück. Wurde kein entsprechendes Feld gefunden, so gibt die Methode einen NULL-Zeiger zurück. |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| SkewAngle | float | Der Winkel, mit dem das Originalbild gegenüber der aufrechten Position gedreht wurde. | rw |
| Movement | daPoint | Die Attribute x und y von daPoint geben die Verschiebung des Originalbildes gegenüber der richtigen Position an. | rw |
| Scale | float | Der Skalierungsfaktor, mit dem das Originalbild in das Analysebild verwandelt wurde. | rw |
| ImageId | ideeString | Der eindeutiger Name des Seitenbildes, wie er durch das Bildarchivierungssystem erzeugt wurde. | rw |
| RoiList | ideeStringList | Die Liste der Namen der Felder, die auf dieser Seite enthalten sind. | r |
| TableCells | ideeStringList | Die Liste der Tabellenzellen, die auf dieser Seite enthalten sind. | rw |
| Columns | int | Die Anzahl der Tabellenspalten auf dieser Seite. | rw |
| Rows | int | Die Anzahl der Tabellenzeilen auf dieser Seite. | rw |
| Name | Beschreibung |
| statPage() | Der Standardkonstruktor |
| statPage(const statPage &obj) | Der Copy-Konstruktor |
| void addRoiName(const ideeString &name) | Fügt einen neuen Feldnamen zu dieser Seite hinzu. |
| void addTableCell(const ideeString &name) | Fügt einen neuen Feldnamen einer Tabellenzellen zu dieser Seite hinzu. |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statRoi() | Der Standardkonstruktor |
| statRoi(const statRoi &obj) | Der Copy-Konstruktor |
| virtual const bool isMeta() const | Gibt true zurück, wenn das Feldobjekt ein Meta-Feld repräsentiert. |
| static statRoiPtr createRoi(ideeString classTyp, ideeString name) | Erzeugt ein Feld, das den Klassentyp classTyp, z.B. TextRoi, und den Namen name hat. |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette. |
| Name | Datentyp | Beschreibung | Zugriff |
| OcrResult | ideeString | Resultat der OCR. | rw |
| DbMatchResult | ideeString | Resultat des DB-Matches. | rw |
| RegExpResult | ideeString | Resultat der regulären Ausdrücke. | rw |
| ProveRestrictionResult | ideeString | Resultat der prüfenden Restriktionskontrolle. | rw |
| CorrectRestrictionResult | ideeString | Resultat der korrigierenden Restriktionskontrolle. | rw |
| AnalyserResult | ideeString | Resultat des Analyser. | rw |
| VerifierResult | ideeString | Resultat der Verifikation. | rw |
| Creator | ideeString | Wurde diese SimpleRoi aus einer MetaRoi erzeugt, so enthält dieses Attribut den Namen dieses Feldes. | rw |
| ImproverRating (mImpRating) | ifcSimpleRoi::ImproverRating | Bewertung des Ergebnisses durch den Improver | rw |
| VerifierAction (mVerAction) | ifcSimpleRoi::VerifierAction | Aktion, die bei der Verifaktion durchgeführt wurde. | rw |
| Name | Beschreibung |
| statSimpleRoi() | Der Standardkonstruktor |
| statSimpleRoi(const statSimpleRoi &obj) | Der Copy-Konstruktor |
| virtual const bool isMeta() const | Gibt true zurück. |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statBarcodeRoi() | Der Standardkonstruktor |
| statBarcodeRoi(const statBarcodeRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statCheckboxRoi() | Der Standardkonstruktor |
| statCheckboxRoi(const statCheckboxRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statDbRoi() | Der Standardkonstruktor |
| statDbRoi(const statDbRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statTextRoi() | Der Standardkonstruktor |
| statTextRoi(const statTextRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statPatternRoi() | Der Standardkonstruktor |
| statPatternRoi(const statPatternRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statMetaRoi() | Der Standardkonstruktor |
| statMetaRoi(const statMetaRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statAddressRoi() | Der Standardkonstruktor |
| statAddressRoi(const statAddressRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statCombiRoi() | Der Standardkonstruktor |
| statCombiRoi(const statCombiRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| TableType | ideeString | Der Typ dieser Tabelle. | rw |
| Columns | int | Die Anzahl der Spalten. | rw |
| Rows | int | Die Anzahl der Zeilen. | rw |
| Header | ideeStringList | Die Liste der Spaltenüberschriften. | rw |
| TableCells | ideeStringList | Die Liste der Namen der Tabellenzellen. | rw |
| Name | Beschreibung |
| statTableRoi() | Der Standardkonstruktor |
| statTableRoi(const statSimpleRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statTopDownRoi() | Der Standardkonstruktor |
| statTopDownRoi(const statTopDownRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) const | Schreiboperator |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
| Name | Datentyp | Beschreibung | Zugriff |
| Path | ideePath | Der Pfad zur Datei, in die geschrieben oder aus der gelesen werden soll. | r |
| Tree | statObjTree* | Der temporäre Baum, der beim Einlesen der Objekte erzeugt wird. | rnc |
| ActDoc | ideeString | Der Name des aktuellen Dokuments. | r |
| ActPage | ideeString | Der Name der aktuellen Seite. | r |
| ActRoi | ideeString | Der Name der aktuellen Roi. | r |
| ActAttr | ideeString | Der Name des aktuelen Attributs. | r |
| Stream | fstream | Der Ein- und Ausgabestream auf die benutzte Datei. | |
| Writing | bool (mWrite) | Dieses Flag zeigt an, ob der Stream zum Schreiben oder Lesen geöffnet wurde. | r |
| Aborted | bool | Dieses Flag zeigt an, ob die Schreib- oder Leseoperation abgebrochen wurde. |
| Name | Beschreibung |
| statAsciiDb(const ideePath &path, const bool bWrite) | Der Konstruktor |
| ˜statAsciiDb() | Der Destruktor |
| void open() throw(ideeFileOpenError) | Öffnet den Stream. |
| void close() throw(ideeFileCloseError) | Schliesst den Stream. |
| void writeChar(char &value) throw(ideeFileWriteError) | Schreibt ein char. |
| void writeBool(bool &value) throw(ideeFileWriteError) | Schreibt ein bool. |
| void writeInt(int &value) throw(ideeFileWriteError) | Schreibt ein int. |
| void writeULong(ulong &value) throw(ideeFileWriteError) | Schreibt ein ulong. |
| void writeFloat(float &value) throw(ideeFileWriteError) | Schreibt ein float. |
| void writeDouble(double &value) throw(ideeFileWriteError) | Schreibt ein double. |
| void writeString(const char *value) throw(ideeFileWriteError) | Schreibt eine C-Zeichenfolge. |
| void readChar(char &value) throw(ideeFileReadError) | Liest ein char. |
| void readBool(bool &value) throw(ideeFileReadError) | Liest ein bool. |
| void readInt(int &value) throw(ideeFileReadError) | Liest ein int. |
| void readULong(ulong &value) throw(ideeFileReadError) | Liest ein ulong. |
| void readFloat(float &value) throw(ideeFileReadError) | Liest ein float. |
| void readDouble(double &value) throw(ideeFileReadError) | Liest ein double. |
| void readString(char *value) throw(ideeFileReadError) | Liest eine C-Zeichenfolge. |
| statAsciiDb& operator>>(statStreamFunc func) throw(ideeFileWriteError) | Dieser Operator erlaubt paramterlose Manipulatoren. |
| statAsciiDb& operator>>(statStreamFunc func) throw (ideeFileReadError) | Dieser Operator erlaubt paramterlose Manipulatoren. |
| statAsciiDb& setAttribName(const ideeString &name) | Wird über einen Manipulator aufgerufen, um den aktuellen Attributnamen zu setzen. |
| statAsciiDb& startDocument(const ideeString &name) | Wird über einen Manipulator aufgerufen, um den aktuellen Dokumentennamen zu setzen. |
| statAsciiDb& endDocument(const ideeString &name) | Wird über einen Manipulator aufgerufen, um den aktuellen Dokumentennamen zu löschen. |
| statAsciiDb& startPage(const ideeString &name) | Wird über einen Manipulator aufgerufen, um den aktuellen Seitennamen zu setzen. |
| statAsciiDb& endPage(const ideeString &name) | Wird über einen Manipulator aufgerufen, um den aktuellen Seitennamen zu löschen. |
| statAsciiDb& startRoi(const ideeString &name) | Wird über einen Manipulator aufgerufen, um den aktuellen Roinamen zu setzen. |
| statAsciiDb& endRoi(const ideeString &name) | Wird über einen Manipulator aufgerufen, um den aktuellen Roinamen zu löschen. |
| ideeString key() const | Erzeugt den Schlüssel für ein Attribut. |
| statNode* getNode() const | Sucht den zum aktuellen Objekt gehörigenden Knoten im Objektbaum. |
| Name | Beschreibung |
| void readFile() | Liest die gesamte Datei zeilenweise, übergibt parseLine den Inhalt der Zeile. |
| void parseLine(const ideeString &line) | Interpretiert die Zeile und fügt die Informationen in den Objektbaum ein. |
| Name | Beschreibung |
| void cancel() | Setzt das Attribut Aborted auf true und wird durch ein Qt-Signal (Knopfdruck) aufgerufen. |
| Name | Datentyp | Beschreibung | Zugriff |
| String | ideeString | Die vom Manipulator übergebene Zeichenkette. | |
| Func | statManipFunc | Zeiger auf Manipulator-Funktion. |
| Name | Beschreibung |
| manip(statManipFunc func, const ideeString& string) | Der Konstruktor |
| Name | Datentyp | Beschreibung | Zugriff |
| Path | ideePath | Der Pfad zur Datei, in die geschrieben werden soll. | r |
| Results | ideeStringField | Die Resultate, die geschrieben werden. Die Tabelle ist zeilenweise angeordnet. | |
| Captions | ideeStringVec | Die Spaltenüberschriften, die in die erste Zeile der Datei geschrieben werden. | |
| Stream | ofstream | Der Dateiausgabestream, der zum Schreiben benutzt wird. |
| Name | Beschreibung |
| statSpreadSheetExport(const ideePath &path, const ideeStringVec &captions, const ideeStringField &results) | Der Konstruktor. |
| ˜statSpreadSheetExport() | Der Destruktor |
| Name | Beschreibung |
| void open() throw (ideeFileOpenError) | Öffnet die Datei und schreibt die Daten in die Datei. Die Spalten werden durch Tabulatoren getrennt. Anschliessend wird die Datei wieder geschlossen. |
| void close() throw (ideeFileCloseError) | Schliesst die Datei. |
| Name | Datentyp | Beschreibung | Zugriff |
| Attribs | ideeStringPairList | Liste der Attribut-Werte-Paare | r |
| Name | Beschreibung |
| statNodeObj() | Der Standardkonstruktor. |
| void addAttribute(const ideeString &name, const ideeString &value) | Füge der Liste von Attributen ein neues hinzu. |
| const ideeString &getAttribute(const ideeString &name) const | Sucht das erste Vorkommen eines Attributes mit den Namen name. |
| const ideeStringList &getAttributes(const ideeString &name) const | Sucht die Vorkommen von Attributen mit den Namen name. |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statObjTree() | Der Standardkonstruktor. |
| void addDocument(const ideeString &name) | Füge eine neues Dokument in den Objektbaum ein. |
| Name | Datentyp | Beschreibung | Zugriff |
| TableRoi | statTableRoiPtr | Zeiger auf eine eventuell in dem Dokument enthaltene Tabelle | |
| GT | bool | Flag, ob es sich bei den extrahierten Daten, um Ground-Truth oder nicht handelt. Setzt das Attribut isGT in statIfcObject. | r |
| LocalDir | ideePath | Der Pfad zu den lokal gespeicherten Pakete, die bearbeitet werden sollen. |
| Name | Beschreibung |
| statExtraction(bool isGT, ideePath localPath= ideePath(''i:\packets'')) | Der Konstruktor. |
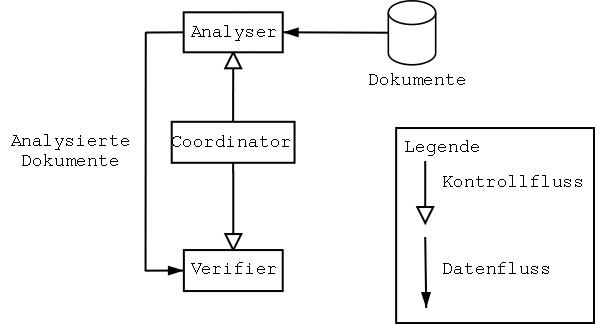
| statDocumentList& extract(dbiControlDbInterface::ImageStackId &stackId) | Extrahiert die Dokumente eines Bildstapels. |
| statDocumentListMap& extract(bool local = false) | Extrahiert die Bildstapel, die vom Benutzer ausgewählt wurden. |
| Name | Beschreibung |
| void extractDoc(const ifcDocument &doc, statDocumentList *dlist) | Extrahiert die Daten eines Dokuments und fügt ein statDocument zu dlist hinzu. |
| void extractPages(const ifcDocument &doc, statDocumentPtr &sDoc) | Extrahiert die Daten der Seiten und fügt sie zu sDoc hinzu. |
| void extractRois(const ifcDocument &doc, statDocumentPtr &sDoc) | Extrahiert die Daten von Feldern und fügt die statRois zu sDoc hinzu. |
| void fillInSimpleRoi(ifcRoiShd &roi, statSimpleRoi *sRoi) | Füllt die eine SimpleRoi betreffende Informationen aus roi in sRoi ein. |
| void fillInMetaRoi(ifcRoiShd &roi, statMetaRoi *sRoi) | Füllt die eine MetaRoi betreffende Informationen aus roi in sRoi ein. |
| void extractTableCells(const ifcDocument &doc, statDocumentPtr &sDoc, ifcPageShd &page, statPagePtr &sPage) | Extrahiert die Tabellenzellen einer Seite und füllt sie in sDoc bzw. sPage ein. Dabei ist zu beachten, dass derzeit pro Dokument nur eine Tabelle geben kann. |
| Name | Beschreibung |
| void stacksParsed(unsigned int nrStacks, unsigned int totalStacks) | Teilt mit, dass nrStacks Bildstapel von insgesamt totalStacks Bildstapel schon bearbeitet wurden. |
| void docsParsed(unsigned int nrDocs, unsigned int totalDocs) | Teilt mit, dass nrDocs Dokumente von insgesamt totalDocss Dokumente eines Bildstapels schon bearbeitet wurden. |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
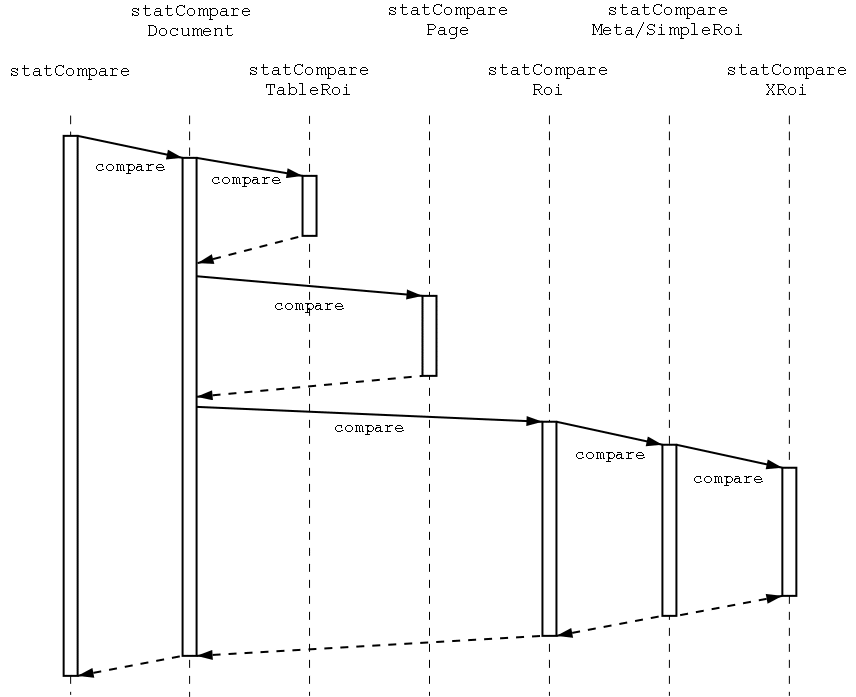
| statCompare(const statDocumentPtr &doc, const statDocumentPtr >) | Der Konstruktor. |
This document was generated using the LaTeX2HTML translator Version 99.2beta8 (1.43)
Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999, Ross Moore, Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -no_subdir -split 0 -show_section_numbers benchmark.tex
The translation was initiated by Jochen Schäfer on 2002-05-02<