![Figure 2.1: Process model editor in MILOS (from [Kön00])](milosprocessmodeller.jpg)
|
Jochen Schäfer
14. April 2003
Department of Computer Science
University of Kaiserslautern
Working group Artificial Intelligence
Prof. Dr. Michael M. Richter
Betreuer:
Prof.Dr. Michael M. Richter
Dr. Harald Holz
In a software engineering (SE) project there are many tasks that have to be dealt with, e.g. software design, project planning, implementation, testing and more. The staff depends on various pieces of information to fulfill their tasks as efficiently as possible. Typically, this information has to be obtained by the particular employees themselves. For the purpose of planning and managing a software project in an automatic and systematic way through process models, Process-centered Software Engineering Environments (PSEE) were developed.
Processes are a set of activities with the aim of reaching a goal. These activities will be called tasks in the following. A process model is a representation of such a process. The key elements of a process model are the tasks, the team members 1.1 that execute these tasks, products that are produced by the tasks, e.g. source code and resources that are needed to execute the tasks [GJ96].
Garg et al [GJ96] specify three areas that are connected by a PSEE:
Each PSEE is designed around a set of heuristics and assumptions about what information is needed by what agent for which task. For this information a variety of access concepts are defined, e.g. a to-do list or that each task has input and output documents.
Most existing approaches have one or more of the following drawbacks:
In order to show how this problem can be addressed, Könnecker [Kön00] introduced the concept of information needs into the existing PSEE MILOS (Minimally Invasive Long-term Organizational Support).
His approach makes it possible to explicitly model recurrent information needs with questions and presents ways to satisfy them by helping finding answers to the questions.
Although his concept constitutes a major advancement, there are some problems with the original implementation that this thesis addresses.
First, there is a high up-front modelling effort, since the original implementation demanded that several aspects of an information need, especially preconditions, are modelled correctly by a group of knowledge engineers1.2. The knowledge department is required to capture and maintain the information needs for each task. The situation becomes especially unpleasant if there is no knowledge department, so that other agents, who usually are not trained in modelling recurrent information needs, are hindered at doing their original work.
Second, there are some structural and conceptual problems that can make maintaining recurrent information needs difficult. E.g. each information need can contain only one information source.
Third, useful information found by colleagues during enactment of earlier similar tasks are not captured and distributed to agents causing superflous information searches.
The goal of this thesis is to lower the burden of managing and handling information resources by providing the agents with tools that allow them to easily capture new information resources and that automatically recommend these resources to certain other agents.
In order to do this we will
In Chapter 2 we briefly describe the PSEE MILOS and the concepts introduced by Könnecker [Kön00]. Furthermore, we describe the refactoring done to overcome some limitations of the original information need support by explaining what the limitations were and how we solved them.
In Chapter 3 we give a short introduction to Collaborative Filtering that will be used for the extensions described in Chapter 4.
In Chapter 4 we will lay out how we want to capture information about the use of information needs, how to distribute them to other users, and how to evolve them so that the distribution of information needs gets more relevant in respect to tasks.
Chapter 5 compares the approach presented here to related works, summarizes it and outlines future work.
The appendix A describes technical and implementational details that do not appear in the thesis. A glossary of important terms used in this thesis is contained in Appendix B.
In the following we will describe the PSEE MILOS and the original information need implementation.
MILOS is a system to support software development in distributed project groups by providing tools for process modelling, project planning and project plan enactment.
MILOS provides a process modelling component to define process models based upon three basic types: processes, methods and parameters. Relations of instances of these types define what needs to be done in a project that is conducted by the process model. A process is a description of tasks that need to be executed to fulfill a project goal. A method describes how a process goal can be achieved. The process model can contain a set of methods for every process. A parameter describes products that are used or created within a process, e.g. the programming specification for the software product. A process model is shown in the process model editor of MILOS (figure 2.1). In this example, the process ``Component-based development'' is decomposed by a method ``Iterative enhancement'' into the subprocesses ``Requirements analysis'', ``Component design'', ``Component implementation'', ``Component testing'' and ``System integration''. For the subprocess ``Component design'' the methods ``OMT'', ``UML'' and ``SDL'' are defined.
While process models are generic reusable descriptions of how the processes should be executed (i.e. containing best-practices with respect to processes), concrete projects have specific needs which are satisfied with a project plan. A project plan can be composed of several process models. A project plan that is derived from the process model in figure 2.1 is shown in the project plan editor of MILOS (figure 2.2).
Project enactment guides the execution of the project plan and leads to creation of the actual products. The MILOS system has a workflow engine to provide the enactment environment. Figure 2.3 shows the To-Do-GUI of MILOS. The current agent Barbara can manage her assigned tasks and the products of each of these tasks. Furthermore, the agent can access messages from events that MILOS creates during project enactment. E.g. if the project plan changes, the affected agents will get notified. The change notification can be defined by ECA (Event Condition Action) rules. This allows on-the-fly changes of project plans.
In his diploma thesis [Kön00] Könnecker introduced the concept of information needs into MILOS. An information need describes a situation where an agent requires certain information items to fulfill his current task or to enhance the quality of the produced objects. Information needs are explicitly modelled in MILOS with information need objects (INO). In this context INOs represent information needs as questions. Furthermore, an INO contains preconditions that formally determine when it arises, and an information source and corresponding access specifications, that help answering the question.
Mayer described in this diploma thesis [May01] how Orenge (Empolis http://www.empolis.com), a case based reasoning (CBR) tool, was integrated into MILOS. In particular, this extension provided the means to characterize tasks by attribute-value-pairs. We will explain the details of the support provided by this extension in section 2.3.
In the following we will explain the concepts, that were introduced in [Kön00].
Planning, management and execution of projects are difficult tasks. To decide what actions have be taken, information has to be accessed, e.g. to decide which agent is suitable for performing a certain task. Further difficulties arise when project plans, requirements and documents change, so that required information changes.
In MILOS, the representation of information needs are covered by the following aspects:
Information sources help satisfying the information need by giving access to information that might be helpful in task enactment.
The motiviation for the original implementation was to enable users of the Information Assistant (IA) to have information resources that may need for fulfilling their tasks presented to them proactively.
In the following we will distinguish between information needs and sources, being abstract concepts, and information need objects (INO) and information source objects (ISO) which are the implementation objects in MILOS.
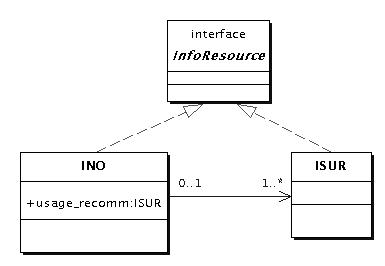
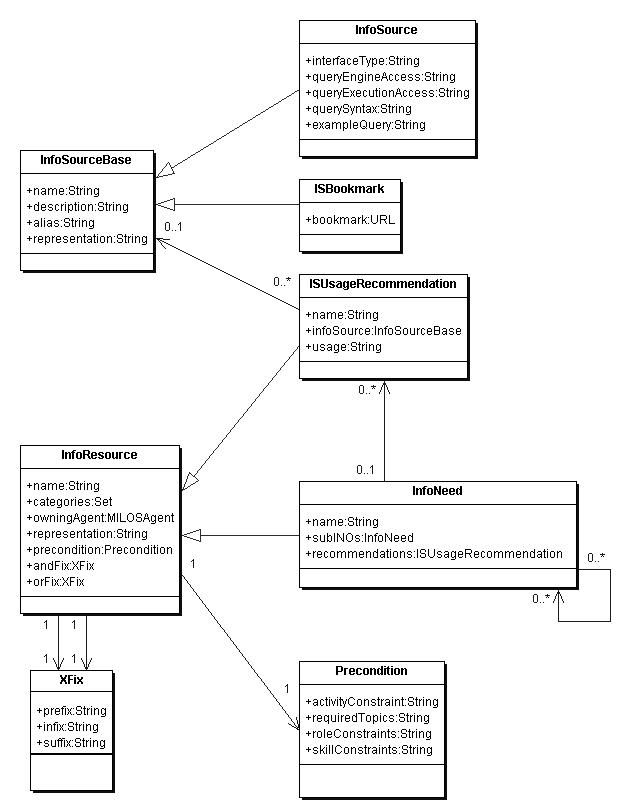
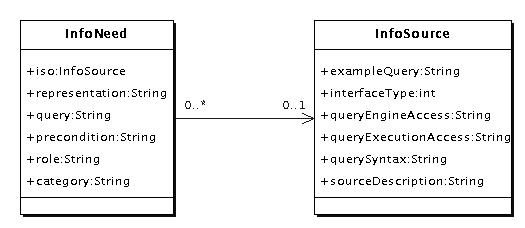
The UML diagram in figure 2.4 shows the interdependence of class InfoNeed, which represents an INO, and class InfoSource, which represents an information source object (ISO). One can recognize that an INO can contain an ISO. But an ISO can be associated with many INOs.
|
An information need as an object (INO) contains the following attributes:
| INO attribute | Example value |
|---|---|
| Representation | What bugs have been reported for the system <system> and the agent <assigned agent>? |
| Information source | Bugzilla Search-for-Bugs |
| Query | ?bug_status=NEW&agent_name=<assigned_agent>&product=<system> |
| Supported role | Programmer |
| Information category | product creation |
| Precondition | system.numberBugs > 0 |
An example for an INO is shown in table 2.1. For further details on this implementation see [Kön00].
An information source has attributes as follows:
| ISO attribute | Example value |
| Information source name | Mozilla.org Search-for-Bugs |
| Contents description | Information source to search for a list of recorded bugs of currently managed systems. |
| Interface type | CGI |
| Query execution access | http://wwwagr.informatik.uni-kl.de/~bugzilla/buglist.cgi |
| Query engine access | http://wwwagr.informatik.uni-kl.de/~bugzilla/query.cgi |
| Query syntax | ?bug_status={NEW, CLOSED, ASSIGNED, VERIFIED}&email1=String&product=System&... |
| Example query | ?bug_status=NEEW&emailtype1=substring&email1=holz&emailassigned_to1=1 |
An example for an ISO is displayed in table 2.2. For further information on representation of information sources consult [Kön00].
Figure 2.5 shows the Information Assistant (IA) as implemented by Könnecker. The tree display in the upper area shows all available information needs sorted by roles and categories and whose precondition holds in the current task's context.
By pressing the button ``Answer'', the user initiate the execution of the information source's query and the result of the query will be presented to the user. The user is also able to access the information source directly by pressing the button ``Access to IS...'' in the lower part of the IA one can create a new INO by posting a question.
The creation and editing of information needs is done with the Information Need Manager. Since INOs are always associated with project plan or process model objects, the knowledge engineer has to select the appropriate object, e.g. ``Implementation'' in figure 2.6, in the upper left part, causing the already created information needs, if any, to be displayed in the upper right part. The knowledge engineer is now able to create new INOs and edit or delete existing information needs.
The attributes of a selected INO are displayed in the lower part of the manager, where they can be edited by pressing the appropriate ``Edit''-button.
For the attribute ``Information Source'' of an INO, the user selects one of the defined ISOs that are specified within the Information Source Manager (cf figure 2.7).
Information sources are created by using the Information Source Manager (figure 2.7). The operation of the Information Source Manager is similar to the operation of the Information Need Manager, except that all ISOs are global to the system, so that there is only one list of ISOs.
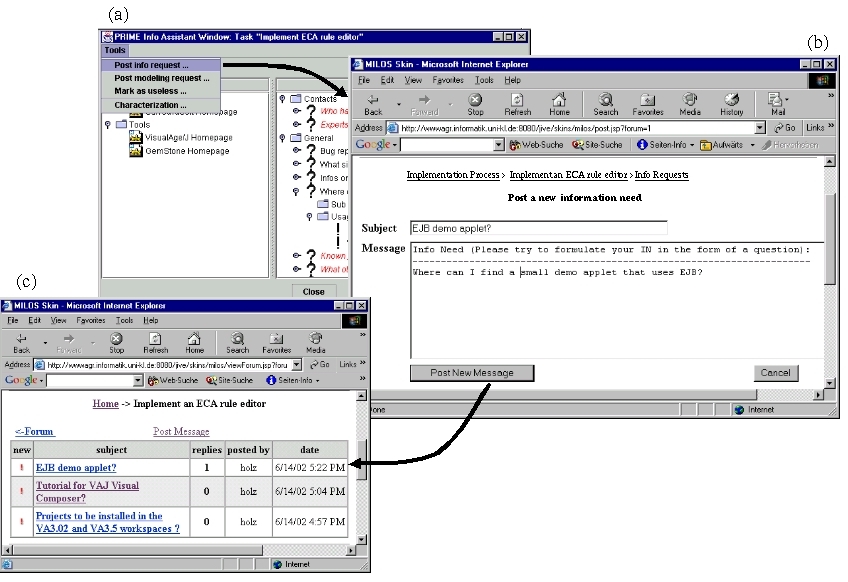
Figure 2.8 depicts an example workflow from IA usage scenario, which we will describe in the following:
Agent Barbara has opened her To-Do-List (a) and selected the task ``Implement WFE component''. By pressing the button ``Info Assistant ...'' she invokes the Information Assistant (b).
The IA displays some information needs in diverse categories. Agent Barbara is interested in information ``What bugs have been report for the project 'Distributed workflow'?'' at the moment, so she select this INO and presses the ``Answer'' button.
The IA computes and executes the query and presents the result, in this example a bug report from Bugzilla.
![figure 2.8: An example IA workflow (from [Kön00]): (a) To-Do-List, (b) Information Assistant, (c) query result](workflow.jpg)
|
The classic approach to Case Based Reasoning (CBR) is to split cases into a case specification part and a solution part. Then the CBR system uses the case specification to find similar cases and adapt the solutions of the retrieved cases to the current problem. The last step is to retain the learned case and save it to the database of known cases. This is called R4 model derived from the four steps Retrieve, Reuse, Revise and Retain [AP94] and is depicted in figure 2.9.
In [Bur00b], Burke argues that Collaborative Filtering has some similarities to case-based reasoning:
In Collaborative Filtering a user votes on items. The item-vote-pair can be regarded in case-based reasoning terms as a case the user adds. The problem in Collaborative Filtering lies in the fact that a prediction has to be made about how much the user will like a new item he has not voted on yet. In case-based reasoning terms, this is a problem situation, where a case is specified containing an item that the user has not voted on. The solution to the problem corresponds to the prediction.
Mayer describes in his diploma thesis [May01] how he integrated similarity-based knowledge management into MILOS with Orenge.
The main concept is the characterization of project plan and workflow objects. This enables the user to annotate the plan elements with attribute-value-pairs, on which one can define similarity measures [Ric,RA99]. To formalize characterization objects and ease the creation of similarity measures, the characterization objects are instances of characterization types that are organized in a type hierarchy. Mayer calls the set of characterization types SEDM (Software Engineering Domain Model) [May01]. Figure 2.10 depicts an excerpt from an example characterization type hierarchy of process types.
|
Every time a process is created in MILOS, a new case containing the characterization of the new process is recorded. So the case base is made up of characterizations of previous processes.
The user can define queries on the characterizations. Furthermore the user is able to define weights for every attribute in a query, thereby emphasizing or deemphasizing the attribute.
The information need support in MILOS as presented above has several limitation and weaknesses which we will explain in this section. For each of the limitations we will furthermore describe how we solve them.
We can divide the problems into structural ones and conceptual ones. The former are determined by deficiencies in the representation of INOs, while the latter are determined by restrictions in the functionality of the IA.
The implementation of Könnecker [Kön00] uses a one-to-one relationship between INO and ISO. This makes it impossible to offer multiple answers for the same information need. If one wanted to know possible sources of information about Java programming, many information sources are available that can help in satisfying the information needs, e.g. agents, who know about Java or web sites about Java. This means that a set of INOs would have to be created that all represent the same information need, but have different information sources.
To solve this issue, we allow every INO to have a list of ISOs. Since every information source needs its own query, the query cannot be specified in an INO anymore. This leads to the concept of ``Information Source Usage Recommendation''2.1 (ISUR), which consists of the query and the ISO. Instead of referencing an ISO, an INO now references the usage recommendation. Section A.1.2 describes the representation of an ISUR.
Each INO has a precondition that controlles whether or not an INO is shown in the IA. One has to put all conditions in one single expression, which would become very hard to maintain over time.
This issue is addressed by the following steps:
Each aspect can specify a condition expressed in a formal language based on Java. Also included is a means to include variable expressions from the MILOS context that can be evaluated with the result replacing the expression. E.g. ``<process:name>'' would be evaluated to the name of the current process. For more details on this parser refer to the appendix A.2.
Furthermore, there is only one type of ISO implemented, which would constrain the possible information sources. The use of the existing ISOs for other types of information sources, e.g. bookmarks, would be possible but counter-intuitive, making usage much more difficult.
Our solution to this issue was to identify the common attributes of all information source objects, such as name and description, and to introduce a new abstract class InfoSourceBase, which contains these common attributes. The old class InfoSource now inherits these attributes from InfoSourceBase. Now we are able to derive as many new types of information sources as we need, e.g. bookmarks (ISBookmark) or agents (ISAgent). The old class hierarchy is shown in figure 2.4, whereas the new class hierarchy is shown in section A.1.
Here we have three issues:
We solved the first issue by allowing that INOs can have more than one category. Furthermore every category can be nested into any other, so a hierarchy of categories can be created. E.g. if we have a category ``EJB'' containing all information needs concerning EJB, the list of contained INOs would be rather long and unmanageable. So we can create sub categories like ``DB technology'' or ``Application servers'' to better manage INOs.
The second issue was solved by introducing the concept of sub information needs according to [Hol02]. Sub information needs are a set of information needs that are referenced by another information need. The sub information needs are supposed to help in satisfying the referencing information need by decomposition into easier information needs. Since sub information needs are itself information needs, they too can have sub information needs.
As a solution to the third issue Holz [Hol02] introduces a specialization relation on INOs that make it possible to refine information needs inherited from a process super type, so that it fits into the context of the subtype.
There are three aspects that need to be refined in an inherited INO: The representation, the precondition and the ISURs. For details on how the specialization relations on each aspect are achieved see [Hol02].
An example for specizialization of the representation is detailed in figure 2.12: The information need ``What tools are available for glass-box testing?'' that is attached to process type ``Glass-Box Testing'' is a specialization of information need ``What tools are available for testing?'' which is attached to the process type ``Testing''.
The original concept was designed to only allow INOs to be created as top level objects in the IA. Use of the IA showed that an agent sometimes wants to add information items without formulating questions. E.g. if a Java programmer wants to bookmark URLs about programming language information, he would need to create an INO with a question like ``Where can I find language information on the programming language Java ?''.
Therefore, we decided to integrate the concept of information resources to enable a more general approach to handling objects in the user's IA. Information resources now subsume INO and ISUR (cf figure 2.3). This concept allows to use ISURs for modelling direct information offers that are not answers to information needs.
The original implementation of the IA only has a single list of information needs. Generally this list will be maintained only by knowledge engineers, since the modelling of such globally available information needs requires knowledge engineering skills. Through this we have a high up-front modelling effort that hinders other agents to do their original work (cf section 2.4.2.3).
Therefore we face two problems:
We solved both problems by introducing a private list in the user's IA. The private list in the agent's IA now enables him to bookmark web pages or documents that he finds useful for completing his task without involving the knowledge department every time. Furthermore, we do not need to assume that there is an existing or functioning knowledge department. Instead we assume that as an effort to make development more efficient, our system is introduced and the appropriate departments or working groups are built up, but not yet working completely.
A user may still have questions about information items, i.e. information needs. To further ease the process of managing information needs we provide support to access discussion forums by means of an ``information request'', which is reflected in the user's IA through an automatically created INO. Examples are shown in figures 2.13. By this means the user is able to get recommendations about possible information sources through internal or external message boards, e.g. the jGuru message boards (http://www.jguru.com).
|
The original approach requires users to make a high effort in modelling the information needs. The modelling effort expresses itself in the need of correct expressions in predicate logic in the preconditions of the information resources. This is especially a problem for users that are not formally trained in creating models.
As a consequence we wish for alternatives that would lower the effort for using and managing resources. One approach we choose is to also allow a privately managed information need list that does not need much modelling effort, if any. For details see section 2.4.2.2.
The following question arises here: How can a user benefit from the private INOs from other users without formalizing the preconditions of INOs? Formalizing the preconditions for the globally available INOs is very important to prevent an information overload.
Based on this private information need list, we created a third information need list, the peer list, which is built by some generic heuristics known from social filtering techniques2.2.
Collaborative Filtering tries to tackle the problem of growing quantity of information by letting users vote on items they are interested in or find relevant. The main assumption for this information management technique is that people with similar votings will have similar interests, which enables the Collaborative Filtering system to recommend items to a user based on his previous recommendations.
The next chapter will describe Collaborative Filtering approaches in more details.
We want to simplify creation and management of information needs by providing agents with access to relevant information resources other agents found useful.
We will use the information recorded and provided by the Orenge case base to identify similar tasks and show their associated information needs.
Collaborative Filtering (CF) [RIS+94] is an information retrieval technique. CF collects ratings of items by users and calculates recommendations for new items. Therefore systems that use CF are often called recommender systems.
The goal is to either guess the rating a user would give to an item or to give recommendations which items could be relevant for a user.
In the literature CF algorithms are distinguished by their approach:
Furthermore, a distinction is made between explicit or implicit voting:
There are a number of issues of recommender systems that must be considered. Since the data space is usually sparsely populated, recommender systems need a lot of votes on items to make useful recommendations. Especially recommendations of new items or for new users tend to be not very useful.
Another issue is that users tend to vote only on items they really like. So most recommender systems let the user make only positive votes.
Usually a predicted vote is calculated by computing the weighted sum of all related votes on the selected item. The weights needed for computing this sum can reflect distance, similarity or correlation.
Memory-based algorithms generally calculate the predicted vote on an item as follows.
The mean vote for user x is defined as:
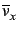 = = |
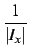 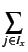 vx, j vx, j |
(3.1) |
with Ix being the set of items that user x already has voted on and vx, j being the votes of user x on item j.
The predicted vote of the active user x on item j is computed as follows:
| px, j = | +  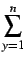 w(x, y) w(x, y) 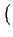 vy, j - vy, j - 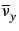  |
(3.2) |
where n is the number of users in the CF database,
that have non-zero weights, i.e. that have voted on j
before. 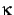 is a normalizing factor, so that the absolute values of the
weights add up to unity. w(x, y) is a
weight function.
is a normalizing factor, so that the absolute values of the
weights add up to unity. w(x, y) is a
weight function.
We can now categorize model based algorithms by their weight function.
Correlation first appeared in the context of the GroupLens project [RIS+94]. Usually the Pearson correlation coefficient will be used as a correlation function. The Pearson correlation is a linear correlation coefficient for two random variables X1 and X2 and is defined as:
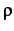 (X1, X2) =
(X1, X2) = 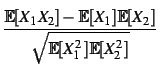
where
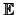
[X]is the expectation for the random variable
X. The value of 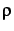 (X1,
X2)is always in the range of [- 1, 1] (cf [Pra01]).
(X1,
X2)is always in the range of [- 1, 1] (cf [Pra01]).
This resolves to the following formula, when used with common formulae:
| w(x, y) = | 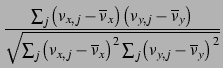 |
(3.3) |
where the summations over j are over the items that both users x and y have voted on.
A common technique of information retrieval to measure the similarity of two documents is to interpret each document as a vector of word frequencies and calculate the similarity as cosine of both vectors [SM83]. We can adopt this technique for CF by letting users take the role of documents and letting votes take the role of word frequencies.
Another possible weight is distance as opposed to similarity.
From a probabilistic point of view we can calculate the expected value of votes, i.e. the probability that the current user will vote with a particular value on an item. For this we need a model that has to be learned. In the following we will consider two alternative probabilistic models, i.e. cluster models and Bayesian network models.
The idea of this model is that the voting vectors of users with similar interests tend to cluster in the data space, forming classes of users. Therefore instead of considering each user's preferences, the model groups the preference of each class of users. For details see [BHK98,RBS00].
An alternative to cluster models are Bayesian network models that are based on the well-known theorem of Bayes. In this model a node represents an item and the states of the nodes correspond to the possible votes. For details see [BHK98,CH97,CHM97].
There are several issue to consider regarding CF.
The biggest issue is the ``missing data'' problem. The sparse distribution of user data makes it hard to generate good recommendations for new items or new users. A new user has not made enough votes so that other users can be considered similar. For new items there are too few votes on them to recommend them to any user. Burke [Bur00b,Bur00a,Bur99] calls this problem ``ramp-up problem''.
One way to address this problem is to introduce default
voting. We assume some default vote value for items for
which we don't have explicit votes. We can use a union of voted
items ( Ix 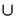 Iy) for matching
instead of an intersection of votes ( Ix
Iy) for matching
instead of an intersection of votes ( Ix 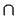 Iy) for the standard algorithm (cf section 3.2.1).
Iy) for the standard algorithm (cf section 3.2.1).
Furthermore one has to consider that CF is very insensitive to preference changes and is subject to statistical anomalies [BHK98]. This is true for memory-based as well as model-based algorithms.
To solve the problem of statistical anomalies we can use a technique called inverse user frequency which is derived from inverse document frequency, a technique common to information retrieval [SM83]. The idea is that very common words are not useful for information retrieval, so weights for these words should be reduced. In the context of CF this translates to the fact that items that are liked by a lot of people are not suited as indicators for correlation. Burke [Bur00b] refers to this problem as the ``banana problem''. Derived from the observation that in the USA bananas are bought by almost all shoppers, as a result bananas would be almost always get a good vote. As a consequence the weight for item ``banana'' should be reduced.
In their observations Breese et.al. [BHK98] find that in 23 out of 24 test cases, there is a statistical significant performance improvement.
We define fj = log  , where nj
is the number of users with votes on item j and n
is the total number of users. As a consequence, if all users
vote on item j, fj becomes zero. In
the case of correlation (equation 3.3)
fj is treated as a frequency, so that a
higher fj will become a higher weight. The
weight function is then defined as:
, where nj
is the number of users with votes on item j and n
is the total number of users. As a consequence, if all users
vote on item j, fj becomes zero. In
the case of correlation (equation 3.3)
fj is treated as a frequency, so that a
higher fj will become a higher weight. The
weight function is then defined as:
| w(x, y) | = | 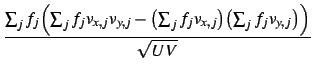 |
(3.4) |
| where | |||
| U | = | 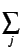 fj fj 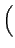 fjvx, j2 -
fjvx, j 2
fjvx, j2 -
fjvx, j 2
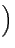 |
|
| V | = | fj fjvy,
j2 - fjvy,
j 2 |
According to [BHK98] Bayesian network and correlation models perform best most of the time. The focus of this empirical analysis was the quality of the recommendations, but it also considered the size of the models and runtime performance. While memory based algorithms tend to use a smaller code base, they model the whole user data base and thus are typically slower than model based algorithms. On the contrary, model based algorithms use a learned model of the user data base, which is smaller than the whole user data base.
In terms of runtime performance, probabilistic models perform much better than memory based models, but one has to consider that this performance advantage is bought at the cost of inaccuracy. This is because the learned model does not reflect the whole knowledge about users' voting behaviours.
Another issue to consider is the impact of learning the probabilistic model, especially if the model changes frequently. To learn a model, the system maintainer has to do off-line learning runs using special test data.
In this chapter we will describe how we use Collaborative Filtering (CF) to support the agents in creating and maintaining information resources needed to fulfill their tasks. In the following we describe how the phases Capture, Distribution and Evolution of information resources are supported.
The problem to be solved is to find a means of calculating the relevance of information resources in regard to the characterization of a task and sorting them by their relevance.
Here is a formal description for the problem:
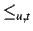 , such that i1 i2 iff user u finds
information resource i2 more relevant than
i1 in the context of t.
, such that i1 i2 iff user u finds
information resource i2 more relevant than
i1 in the context of t.Our objective is to capture information about information resources, so that we can make recommendations about them. We distinguish two kinds of information: (i) newly created information resources and (ii) votings on information resources. We will do implicit voting wherever possible.
We will do this by applying the following heuristics4.1:
The captured information will be recorded separately for each task. For details on the stored data see section 4.1.1.
In this section, we will motivate the heuristics.
First, we think that if the user makes the effort to actually access a global information resource, then it is worth to be counted as being voted on (item 1). If the user however feels that the information resource was not useful for his task after all, he can mark it USELESS (item 2). Because of the effort of privately creating information resources we automatically label such information resources as SHOWN (item 3).
Any recommendation that is accessed will also be counted as voted on (item 4).
Because recommendations are usually distributed very sparsely (cf section 3.2.3), we expect a lot of undefined values, so we introduce a default voting (item 5). The meaning of this default voting is that the user has not voted on the item.
The motivation for recording captured information by task is two-fold: First, we want to do task-specific recommendations, so that it does not seem to be appropriate to compare all captured information globally. Secondly, we argue that although an information resource may be useful for one task, it may be less useful for another task. E.g. consider as an information resource the installation manual of a development environment, which is attached to all tasks that use this development environment as a tool. If the task at hand is concerned with the setup of the development environment, the information resource is probably useful. If the task is only concerned with programming using this tool, that information may not be very useful. Therefore the possibility of recording distinct votings on information resources in different tasks is required.
For the votes we set the values as follows:
A consequence of these values is that a division by zero is possible, so that this fact has to be considered.
The mean vote (formula 3.1) can contain a division by zero, if user x has not voted. In such a case it is safe to set the mean vote to DEFAULT, since the default vote has the meaning of not having voted.
The correlation weight (formula 3.3) can become undefined in many situations. The weight has then to be set to 0, since this value means there is no linear correlation between both users at all (cf [Lan03]).
Finally, the predicted vote (formula 3.2) can have a
division by zero through the factor , if no votes are made at all. can be set to 0, since the whole
term will become 0 anyway.
To be useful, the captured information must be used to present relevant information resources in regard to the current task to the user. This section describes how this distribution is done.
The recommender should do its suggestions proactively, i.e. without requiring the user to initiate the recommendation. So the recommendations will be displayed automatically in the middle section of the user's IA.
Furthermore the user should be able to focus on a recommendation by selecting it. Then the user's IA should display information resources which were accessed by users that also accessed this particular information resource. Figure 4.1 depicts how this will look. In this example, one can see privately created and peer recommended information resources. Since the user created the information needs ``EJB specification'' and ``EJB Tutorial'', the IA recommends the information need ``EJB demo applet?''. By selecting this information need, the bookmarks ``VisualAge EJB FAQ'' and ``JBoss Webserver Tutorial'' are selected.
As a Collaborative Filtering algorithm we use the standard memory-based approach with the Pearson correlation as a weight function (cf formula 3.3).
Our aim is to make task-specific recommendations, i.e. to make recommendations based on information about the user's current task that is available in the form of the task's characterization (cf section 2.3.1).
In order to make these task-specific recommendations, we assume to have the following information available:
First, we have captured recommendation data and attached it to the task's characterization (cf section 4.2).
Second, we can define similarity measures with Orenge tools which define how items of a particular characterization type can be compared. With these measures we can find out whether some information resources have some characterization attributes similar to those of the current task.
We extend the Pearson correlation (formula 3.3) by including a similarity coefficient as follows:
| w(x, y) = | |
(4.1) |
where sim(tx, y, j) is the similarity of task tx and the most similar task of user y, in that user y has voted on information resource j. With this terms, we emphasize information resources belonging to similar tasks. By this means users will get better recommendations in regard to task relevance.
All this information we gathered will be used in the Collaborative Filtering algorithm in which information resources take the role of items.
The implementation is based on the algorithm 1.
Furthermore, the agent can make votings on the recommended information resources themselves to further emphasize the relevance of a particular information resource.
The following example is situated in the GUI programming group of a software company. The purpose of this group is to build the GUIs for the company's software.
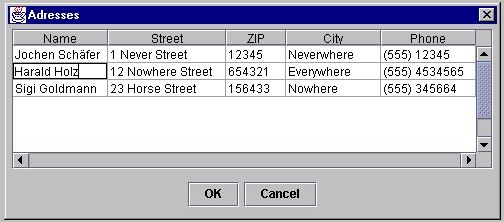
Agent Bob has the task to implement a dialog with the Swing toolkit, with which he is not familiar. This dialog should show the entries of an address book, stored in an Oracle data base. To achieve this goal, he has to use the JTable class, which implements a generic table.
Agent Anna has some experience with Swing and with JTable in particular. She has implemented an application with a table that allowed to view database entries from a DB2 data base.
A mock-up GUI of the address book dialog to be implemented by Bob can be seen in figure 4.2.
The following section describes the tasks of agents Anna and Bob. These task descriptions formalize the characteristics of the tasks. In the following, we adopt the task representation introduced by [Hol02] and set the descriptions itself in typewriter font, e.g. t.name, where ``name'' denotes an attribute of object ``t''. Around set values we put braces, e.g. {A, B}. We call Anna's task t and Bob's task s. Both tasks have characterizations of type ``Implementation Process''.
As we can see the tasks of Anna and Bob have one difference, i.e. whereas Anna had to program a data base viewer for DB2, Bob has to implement a viewer for Oracle.
The following information resources were used in this example. Table 4.1 depicts the bookmarks in the first column, the owner4.4 of the information resources in the second column, and the category of the information resource in the third column. The fourth column depicts the object, which the information resource is attached to.
| Information resources | Owner | Category | Attached to object | |
|---|---|---|---|---|
| JDK 1.2 API Documentation http://java.sun.com/products/jdk1.2/docs/api | global | Java | Implementation process | |
| Sun Java Swing tutorial http://java.sun.com/docs/books/tutorial/uiswing | global | Java | Implementation process | |
| jGuru Swing FAQ http://www.jguru.com/faq/Swing | global | Java | Implementation process | |
| VisualAge Database Access tutorial for DB2 | global | Databases | Implementation process | |
| Sun Swing examples http://developer.java.sun.com/developer/codesamples/swing.html | Anna | Java | Implement DB2 address book | |
| jGuru Swing forum http://www.jguru.com/forums/Swing | Anna | Java | Implement DB2 address book | |
| Google search on "JTable" http://www.google.de/search?q=JTable | Anna | Java | Implement DB2 address book | |
| DB2 manual | Anna | Databases | Implement DB2 address book | |
| Google search on "JTable" and "sample" http://www.google.de/search?q=JTable | Bob | Java | Implement Oracle address book | |
| Oracle manual | Bob | Databases | Implement Oracle address book |
We assume the following characterization for the following items:
In this section we want to make clear how we picture the use of the recommendation system. The aim of this section is to make clear how the recommendation system should ideally work.
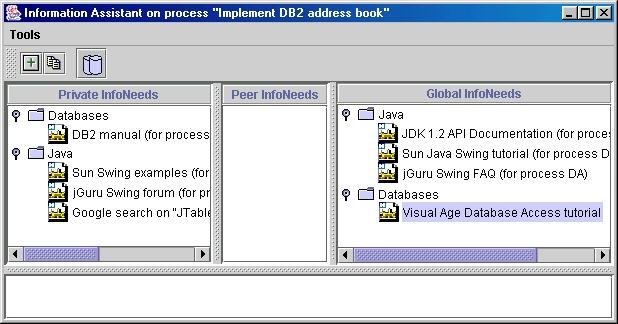
Agent Anna had to program a database viewer, therefore she had to use the Swing Tables API. The task in the project plan is called ``Implement DB2 address dialog'' and has a characterization of type ``Implementation Process'' (cf figure 2.10). From the To-Do dialog she opens the Information Assistant for this task.
The IA would be resemble the one displayed in figure 4.3. On the right, there is the section of globally available information needs. On the left, there is the section of private information needs, i.e. information needs created by Anna and manageable only by Anna.
The normal situation would be that at least some common characterizations and their information resources were created by the knowledge department. There are already several categorized global information needs available such as ``Where can I find documents on Java?''. Also shown is the ISUR ``Java Homepage'', which is a book mark to http://java.sun.com. In the middle section the peer information will be displayed. This information is recommended by the system we will describe here.
Furthermore, we can see in figure 4.3 that Anna has created some additional information resources for her own use as detailed in section 4.4.2. From the global list of information resources Anna executed the jGuru Swing FAQ and VAJ DB access tutorial information resources.
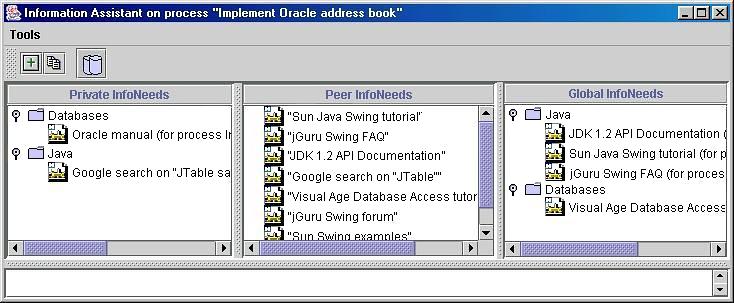
Now Bob is assigned his task. When he opens his IA, he should have some recommendations, as depicted in figure 4.4.
Bob should have recommendations for the following information resources:
All these information resources have characterization that the users can attach. Item2 is not shown on the peer list since the characterization does not fit concerning the attribute keyTopic. The attribute keyTopic of item2 contains the value ``DB2'', whereas the attribute keyTopic of task s does not contain ``DB2''.
This section's aim is to show how an actual calculation of a recommendation value is done. For simplicity's sake, we assume here that the similarity of tasks s and t are 1.0. This is reasonable, because (i) we can set similarity of tasks to 1.0 if no similarity measure is present, and (ii) in this example, the information resources are all in the same categories and the characterization type of both is the same.
Table 4.2 depicts the matrix needed to calculate the recommendation value.
| Information Resources \ Agents | Anna | Bob |
|---|---|---|
| JDK 1.2 API documentation | SHOWN | SHOWN |
| Sun Java Swing tutorial | SHOWN | SHOWN |
| jGuru Swing FAQ | SHOWN | SHOWN |
| VAJ DB Access tutorial for DB2 | SHOWN | DEFAULT |
| Sun Swing examples | SHOWN | DEFAULT |
| jGuru Swing forum | SHOWN | DEFAULT |
| Google search on „JTable„ | SHOWN | DEFAULT |
| DB2 manual | SHOWN | DEFAULT |
| Google search on „JTable sample„ | DEFAULT | SHOWN |
| Oracle manual | DEFAULT | SHOWN |
Now the mean vote of Anna is vAnna = 8 and
that of Bob is vBob = 5. The correlation
between Anna and Bob computes to w(Anna,
Bob) = - 100. The predicted vote for the information
resource ``VAJ DB Access tutorial for DB2'' then computes to
pBob, VAJ DB = 4. This decomposes the
following way: The summation term of formula 3.2 computes to -200
and because the absolute sum of all votes is 200, = 1/200.
Since we had to deal with the aforementioned ramp-up problem (cf section 3.2.3) of Collaborative Filtering and the possibly missing knowledge department, we thought of the following solution.
Because of the missing knowledge department, we assume that there are no or just a few globally defined information resources. We further assume that there are not enough votes to make good recommendations and that users do not correlate well.
For bootstraping purposes we will allow users to access all known private information resources of all others users. This will enable the user to make votings by looking at the information resources of others.
To make access easier the list of information resources will be sorted by the following three criteria in descending relevance:
This sorting will provide the agent with a means of accessing relevant information resources in regard to his current task first, but still have access to all known privately created information resources.
We think that this approach is feasible since we cannot assume the presence of a knowledge department that could initialize the voting data. Furthermore we have no training data, so that we cannot train a model-based CF system.
We expect that through this approach the ramp-up problem is not solved, but at least lessened. This approach will especially help the agents with their information searches if new kinds of projects are started. Consider a company that did RMI4.5 programming project in the past, and now has an assignment for a CORBA4.6 programming project. The agent will certainly not find any direct information on CORBA in the information data of the company, but they can at least get some ideas about distributed computing problems and where to find further information.
The aspect of evolution in our concept is expressed by three points:
First, voting makes it possible to get feedback about the agents' behaviour in regard to information retrieval, which is further emphasized by voting on the recommended information.
Second, we allow the agents to access the characterization type hierarchy and all instances of the respective types and attach privately created information resources to them. Furthermore the agent can attach characterizations to the information resource, e.g. by specifying the key topics of the information resource. This will allow finer control over the task-specific relevance. Consider a newly employed programmer, for example, who added as a information resource a document about the coding guidelines of his company. This is surely important for the task at hand, but is also important to other implementation processes, so it would be helpful to attach this information resource to the characterization type ``Implementation process'' (cf figure 2.10).
Third, a modeling request will be posted in a special discussion forum, similar to the information request (cf section 2.4.2.2). This will allow communication of the agents with the knowledge department. The topic of these discussions is the modelling of privately created information resources and integration into the global list of information resources. By this means the knowledge department is supported in creating appropriate information resources by the agents, who are using these resources in everyday work.
We expect that the system will gradually make better recommendations for established users and tasks. For new kind of tasks, e.g. Java programs instead of C programs, the recommendations will neither be plentiful nor particularily well suited. But again, with continuous use of our concept, the results will get better.
We further expect that, since we include the categorization of the information resources in the captured recommendation data, an ``oral tradition'' of categorizing information resources will evolve.
In this chapter, we summarize our approach, relate it with other works and outline future work.
In the introduction (cf chapter 1) we described three issues we wanted to remedy:
The first issue has been addressed in this thesis by introducing privately managed lists of information resources (cf section 2.4.2.2), which proved to be a good tool for dealing with information resources. Our observations showed that the ability to privately create information resources eases the task of software development by circumventing the high modelling effort.
The second issue has been addressed by refactoring the former concept of information needs by Könnecker to remedy the structural and conceptual problems, as laid out in chapter 2. This allowed us to solve the third issue.
The third issue has been addressed by creating a peer list of information resources by using task-specific information and Collaborative Filtering (cf chapter 4). We selected a memory-based correlation approach for the CF algorithm, which we extend by a task-specific term (cf formula 4.1). We select the set of information resources, for which a recommendation should be computed, by using task-specific information from the MILOS system (cf algorithm 1).
Resnick et al [RIS+94] extend Usenet news by means of special news servers, called Better Bit Bureaus (BBB), that compute scores predicting how much the user will like articles, and collect the ratings after the user read an article.
In the GroupLens system, a user rates an article by assigning to it a number from 1 to 5, with 5 being the highest rating. Optionally, the system can also keep track of the time the user needed to read the article. In order to help to identify ratings from the same person, but still preserving anonymity, the user chooses a pseudonym, which doesn't have to be same name as the one used to post articles. To make a prediction, a BBB uses a memory-based algorithm with a Pearson correlation as described in section 3.2.
The main assumption is that people who made similar votes will vote similarly in the future. Another important assumption is that people may agree in some topics, but not others, e.g. they may agree on the evaluation of technical articles, but not on jokes. Therefore ratings are separated for each newsgroup.
Although being one of the first groups to use Collaborative Filtering, Resnick et al already pointed out that during an initial phase recommender systems have problems making a recommendation. They also indicate that further research on the issue of performance had to be made.
Our recommendation system follows GroupLens with the assumption that it is necessary to separate the voting information, but we also use the information about the user's current task. Furthermore, we are able to use arbitrary information sources, not only newsgroups.
The CALVIN (Context Accumulation for Learning Varied Informative Notes) project investigates lessons learned systems that support the process of finding information relevant to a particular research task [LBMW]. The CALVIN system has three primary tasks:
CALVIN describes a user's research context by three classes of indices: (i) the user-specified task, (ii) a set of topics on which the user searches information, and (iii) a description of the content of information resources consulted by the user (i.e. a set of automatically generated keywords). As the user browses, the system maintains a global context of the user-viewed resources (i.e. user selected task and topics) and compares it with former contexts. If the similarity between two contexts exceeds a certain threshold, both are considered similar and the resources of the former context are presented to the user.
Three lessons can be learned by using CALVIN. First, it stores cases containing information about resources that previous users found useful in a similar context. Second, it captures lessons about annotations that the user attaches to information resources. Third, CALVIN supports the use of concept mapping tools for recording, elucidation and sharing of lessons on important concepts and relationships in the domain.
The approach taken by the CALVIN system does not take into account that users may have different skills and preferences, which will cause CALVIN to recommend irrelevant information resources to the user. Our approach addresses this issue by combining Collaborative Filtering with similarity-based retrieval.
CASPER is a research project that investigates how artificial intelligence can be used to improve information access [RBS00]. In addition to the information items accessed, CASPAR uses three types of implicit relevancy information in its user profiles for its recommendation algorithm:
CASPER uses a cluster-based approach to Collaborative Filtering that can identify both direct and indirect user relationships. User profiles become clustered into virtual communities. Users in such a community correlate quite well with each other, but not with users in other communities. A community is built by identifying the maximal set of users such that every user has a similarity value greater than a threshold with at least another community member.
Rather than applying an memory-based algorithm to the k-nearest neighbours, CASPER recommends the most frequently occured information items in the target user's virtual community. This leads to a richer recommendation base by identifying a larger set of users similar to the target user. A disadvantage of this approach is that CASPER is not able to evaluate direct links between all pairs of users.
Our approach neither uses any of these data types nor applies a cluster-based algorithm. Future work has to assess the value and applicability of this approach to MILOS.
Most Collaborative Filtering approaches assume that all users are equal concerning their role. PHOAKS (People Helping One Another Know Stuff) [THA+97] assumes that users tend to play distinct producer or consumer roles, which are specialized and different. The consequence of this is that a few participants in the discussions make the effort to recommend a resource to others while the rest consumes this information. As a consequence, the frequency of recommendation of a resource is considered as a means of quality measure.
PHOAKS also reuses recommendations from online conversations. This is done by scanning the messages for URLs according to four rules:
The extraction of recommendations allows for implicit voting, i.e. without requiring any user of PHOAKS to vote for a recommendation.
Our approach also assumes that users take distinct roles, but it does not make assumptions about the consumer or producer roles. Our concept is that each user automatically takes the producer role, while automatically taking the consumer role getting recommendations. Consequently, the distinction between consumer and producer does not seem to fit well.
Entree [RKB97, BHY96] is a restaurant recommender system that uses a hybrid CBR/CF approach.
Burke argues in [Bur00a, Bur99, Bur00b] that by combining Case-based Reasoning and Collaborative Filtering it is possible to overcome the weaknesses of both techniques. Table 5.1 depicts the trade-offs of both techniques and of an ideal hybrid.
| Technique | Pluses | Minuses |
|---|---|---|
| Knowledge-Based | A. No ramp-up required | H. Knowledge engineering |
| B. Detailed qualitative preference feedback | I. Suggestions ability is static | C. Sensitive to preference changes |
| Collaborative Filtering | D. Can identify niches precisely | J. Quality depended on large historical data set |
| E. Domain knowledge not needed | K. Subject to statistical anomalies on data | |
| F. Quality improves over time | L. Insensitive to preference changes | |
| G. Personalized recommendations | ||
| Ideal hybrid | A, B, C, D, F, G | H |
The retrieval strategy uses a cascading approach. First a CBR retrieval is executed and the result is sorted into buckets by similarity. Since the system only presents a fixed number of recommendations, e.g. ten, it can happen that a bucket has more items than is needed for the recommendation, e.g. the topmost bucket contains 20 items. Burke considers this result ``under-discriminated''. Eliminating under-discriminated results would require further knowledge engineering and perhaps a more detailed representation of the items.
Burke now argues that Collaborative Filtering can help to find the best recommendations of the under-discriminated result. This is done by ranking each item of the under-discriminated result. Here the ramp-up problem of Collaborative Filtering is not very risky, because if the worst thing, random ratings, happens, the system can still select equally good items.
Our approach shares with ENTREE the concept of refining the results from similarity-based retrievals with Collaborative Filtering. Both differ in the conceptual distinction between the set of objects on which similarity is computed (tasks) and on which Collaborative Filtering is applied (information resources associated with tasks).
Google is not per se a Collaborative Filtering system, but uses some techniques common to such systems. Google was created as a research web search prototype at the Stanford University by Sergey Brin and Lawrence Page [BP98].
Common web search engines at that time mostly rated web pages on the frequency of word occurrence. Because of that technique web designers soon realized that by putting certain words into non-visible parts of the document, they could push their document to the top of the search result lists.
Brin and Page added implicit voting to their rating algorithm called PageRank. The more links (citations) to a web page can be found in the known web space, the higher the page gets rated. Also the higher the page rankings of the citing pages are, the higher the page ranking of the cited page gets. In terms of Collaborative Filtering this means that the citing page votes for the linked page.
A problem not mentioned in [BP98] is that web sites with very specialized topics, which are cited only by a few other web sites, do not get a high page ranking.
An important future task is to built up a database of training cases, so that the implementation and its future iterations can be tested in real-world scenarios and to make the switch to model-based Collaborative Filtering algorithms possible. It is important to further investigate the benefits of our Collaborative Filtering approach, how to further improve it and whether other CF approaches could be beneficial.
Another possibility to make recommendations would be to sort the voting information by categories instead by tasks, if the user requests that. Although this concept has to be further investigated, we feel that it could be useful to have recommendation on certain categories. This would give the recommendation another focus possibly uncovering more relevant task-specific information.
Another issue is the investigation of a suitable similarity measure for tasks. We expect that there is no single way to define such a similarity measure. A possible solution would be to use a particular similarity measure by default. Other similarity measures can be presented to user, who can select the measures he thinks of as appropriate in the context of his current task.
We described in chapter 2, why and how we refactored the class structure in MILOS. The UML class diagramm in figure A.1 depicts a snapshot of the class dependencies concerning information resources. We showed only the aspects, that are important for this thesis.
An ISUR contains the following aspects:
An example of an ISUR object is depicted in table A.1.
| Attribute | Example value |
|---|---|
| Information source | JDK 1.2 language specification |
| Process type | Implementation process |
| Activity constraints | Programming language is Java 2 |
| Role constraints | Useful for role "programmer" |
| Skill contraints | Programmer is not a Java expert |
| Topic constraints | Useful for using exceptions |
| Usage direction | See chapter 3 |
The class CapturingContainer is used to hold the information we need for using Collaborative Filtering and contains the following aspects:
All aspects except the both first directly to the aspects of the formal description of the voting (cf section 4.1.1). The both information resources correspond to the information resource aspect.
This distinction was made because it is possible that the accessed information resource is part of an information need, which is the item we actually want to recommend. If the information resource is not part of an information resource, i.e. if the information resource is a bookmark or ISUR, which is created at top level, then both aspects are set to this information resources.
The distinction is important, since an information need can contain more than one information source (an ISUR), that can be accessed. Each access of such information source is a different case, although the item which has to be recommended is actually the information need.
The query expression parser was integrated into MILOS by Mayer, who created a Java expression parser with SableCC, a pure Java Compiler compiler (http://www.sablecc.org). It is used to resolve queries, representation and preconditions in the information resource concept.
All expressions will be evaluated in an evaluation context, that defines, how variables are resolved. The formal language that is accepted by the query expression parser, is built up from three parts:
The parser supports five pseudo-variables as follows:
As a more elaborated example consider that one wants to know if the current agent has at least one privately created information resource for the current task, he would use the following expression:
<Orenge:task.inforesources.detect[each.owningAgent == agent]>
The expression task.inforesources resolves to the list of inforesources attached to the current task, to which we can apply detect. The condition each.owningAgent == agent tests if the owning agent of the current list element is equal to the current agent.
Capture, Distribution and Evolution of Information Needs in a Process-Oriented Knowledge Management Environment
This document was generated using the LaTeX2 HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999, Ross Moore, Mathematics Department, Macquarie University, Sydney.

![Figure 2.2: Project plan editor in MILOS (from [Kön00])](milosprojectmodeller.jpg)
![Figure 2.3: To-Do-GUI of MILOS (from [Kön00])](todolist.jpg)
![Figure 2.5: The Information Assistant (from [Kön00]](oldia.jpg)
![Figure 2.6: The Information Need Manager (from [Kön00])](inmanager.jpg)
![Figure 2.7: The Information Source Manager (from [Kön00])](ismanager.jpg)
![Figure 2.9: CBR cycle according to Aamodt and Plaza [AP94]](cbrcycle.jpg)
![Figure 2.12: Specialization example according to [Hol02]](specialization.jpg)