|
Jochen Schäfer
Zur Optimierung des Systems ist es notwendig, objektiv nachvollziehbare Aussagen über die Erkennungsqualität zu treffen. Diese Verfahren werden in dieser Arbeit beschrieben.
Ein Dokumentenanalysesystem hat das Ziel, auf Papier vorhandene Informationen elektronisch verfügbar zu machen. Dazu werden Dokumente, die zuvor eingescannt wurden, vom System klassifiziert und relevante Informationen extrahiert.
Das Werkzeug, das in dieser Projektarbeit beschrieben werden soll, dient dazu, die korrekte Funktion der Systemkomponenten bei der Entwicklung zu prüfen, sowie Verbesserungen bzw. Verschlechterungen einzelner Komponenten detailliert zu untersuchen. Das Werkzeug soll es weiterhin ermöglichen, innerhalb des Systems objektive Daten über die Qualität der extrahierten Texte zu sammeln. Dabei wird darauf geachtet, dass das System erweiterbar und flexibel bleibt.
Das in dieser Arbeit beschriebene Verfahren zur Einschätzung der Erkennungsqualität des Dokumentenanalysesytems soll es zum Beispiel für den Vertrieb einfacher machen, gegenüber Kunden objektive Aussagen über die Erkennungsraten des System zu machen. Dieses ist auch in vertragsrechtlicher Hinsicht wichtig, da bei Nichteinhaltung bestimmter zugesicherter Mindestraten Vertragsstrafen drohen. Ebenso ist es für den Vertrieb wichtig, zukünftige Kunden zu überzeugen.
Auch für die Entwicklungsabteilung ist die Kenntnis der Erkennungsraten wichtig, da damit die Schwachstellen des Systems identifiziert und verbessert werden können. Außerdem kann anhand der ermittelten Daten überprüft werden, ob sich das System oder Teile davon verbessert oder verschlechtert haben. Dies erlaubt dem Entwickler des Systems, dieses zu optimieren.
Nach der Erklärung einiger Begriffe wird das verwendete Dokumentenanalysesystem beschrieben.
Danach auf den aktuellen Stand der Forschung eingegangen. Hier werden inbesondere verschiedene Techniken aus der Forschung beschrieben.
Von diesem Stand der Technik ausgehend wird der in dieser Arbeit beschriebene Ansatz vorgestellt. Darauf folgen die Durchführung dieses Ansatzes sowie die Ergebnisse.
Die Arbeit wird mit einem Ausblick abgeschlossen.
In diesem Abschnitt werden einige wichtige Begriffe erklärt, die für das Verständnis der Projektarbeit grundlegend sind.
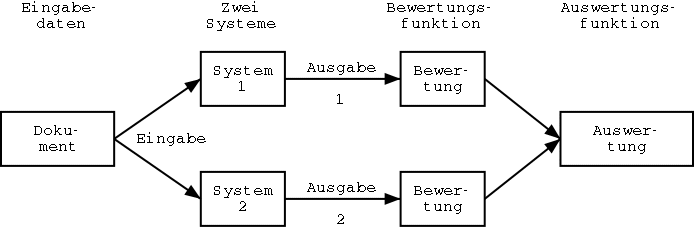
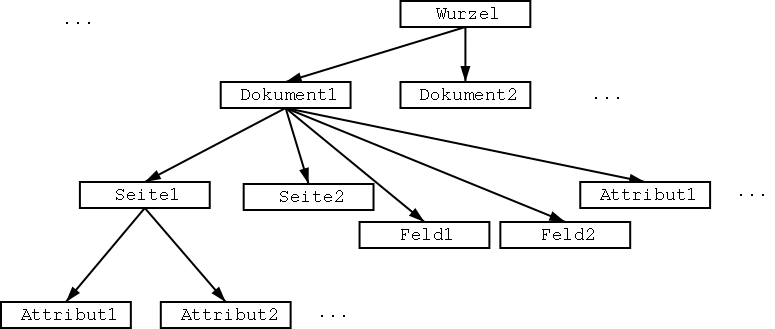
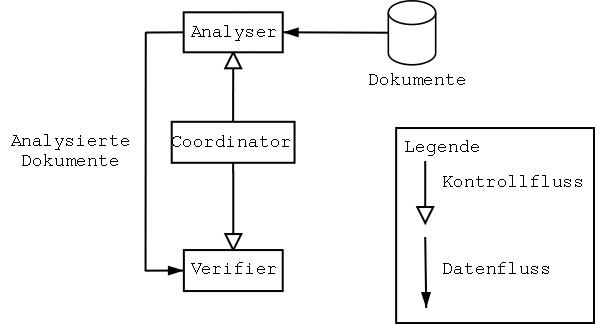
In diesem Kapitel werden die einzelnen Komponenten des Dokumentenanalysesystems beschrieben. Die Abbildung 2.1 gibt eine Übersicht des Systems. Das System besteht aus den folgenden Teilen:
Dokumentendefinitionen sind das Ergebnis des Trainings mit dem FormManager (s. Abschnitt 2.1). Jede Dokumentendefinition repräsentiert dabei eine Dokumentenklasse, die alle für die Erkennung notwendigen Informationen über die Klassifikation, die enthaltenen Felder und Felderprüfungen zusammenfasst.
Für die Felderdefinition eines Dokumentes ist es nötig, die Merkmale festzulegen, die für die jeweilige Dokumentenklasse auszeichnend sind. Die in Abschnitt 2.2.4.3 beschriebenen Klassifikationskomponenten FormClas, TableClas und PatternClas können diese Merkmale zur Klassifikation der Dokumente verwenden.
Beispielsweise erkennt FormClas Dokumente anhand des Layout. Anhand des spezifischen Layouts eines Steuerformular kann dieses dann als solches erkannt werden.
Die Felderdefinition legt fest, wo die Felder des Dokumentes zu finden sind. Am einfachsten ist dies für Formulare, da dort die Position der Felder fest ist. Beispielsweise findet man das Adressfeld eines Formulars zur Steuererklärung immer (zumindest für ein Jahr) an der gleichen Stelle. Bei Dokumenten mit freier Struktur ist das Positionieren der Felder etwas schwieriger, jedoch bietet das Dokumentenanalysesystem die Möglichkeit, nach Bereichen auf dem Dokument zu suchen, die bestimmten, vom Benutzer festzulegenden Regeln genügen. Möchte man etwa das Datum auf einem Dokument finden, das eine freie Form hat, also kein Formular ist, dann könnte man als Suchmuster ``Datum:`` suchen und das Feld rechts von diesem Text positionieren.
Verbünde schränken die Wertemenge zusammenhängender Felder ein. Dazu werden sogenannte Constraints angegeben (s. Abschnitt 2.2.4.7). Bei einer Adresse z.B. können die Inhalte der Felder durch eine Adressdatenbank abgeglichen werden, um möglichst plausible Werte zu erhalten. Enthält die Datenbank etwa einen Eintrag ``Petra Mustermann'', die Buchstabenerkennung liefert aber ``Peter Mustermann'', wird angenommen, dass der Datenbankeintrag wahrscheinlich der richtige Wert ist (s. Abschnitt 2.2.4.7).
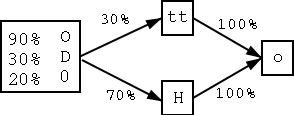
Die OCR (engl. Optical Character Recognition) erkennt die einzelnen Buchstabem der Wortsegmente, die bei der Segmentierung erzeugt wurden. Dabei wird ein Graph mit möglichen Alternativen erzeugt. Jeder Knoten repräsentiert hierbei ein Segment. Ein Knoten beinhaltet die einzelnen Alternativen für dieses Segment mit einer Wahrscheinlichkeit, dass die jeweilige Alternative die Richtige ist. Beispielsweise werden die Zeichen für Eins (``1'') und für ein kleines L (``l'') oft sehr ähnlich (manchmal sogar gleich) dargestellt. Im OCR-Graph würde in einem Knoten beide alternativen dargestellt. Außerdem enthält der OCR-Graph Segmentierungsalternativen. Bei dem Wort ``Otto'' beispielsweise könnte die OCR einen Knoten für das Segment ``tt'' und einen Knoten für das Segment ``H'' erzeugen. Die Kanten an diesen Knoten haben ihrerseits Gewichte.
Die Dokumentenklassifikation versucht den Typ des Dokumentes und die Anzahl der Seiten zu erkennen. Dabei gibt es drei Komponenten:
Der Adresslocalizer/Adressplitter sucht auf dem Dokument Adressen und zerteilt sie in Vorname, Name etc.
Der Pattern Matcher extrahiert anhand von regulären Ausdrücken Informationen aus dem Dokument.
Der Table Analyser extrahiert aus einer Tabelle die enthaltenen Tabellenzellenfelder.
Bei der Extraktion von Informationen aus Dokumenten hat man das Problem, ob und wieweit man den Ergebnissen einer OCR vertrauen kann. Insbesondere sind die Ergebnisse verschiedener OCR-Engines auf dem gleichem Dokument oft sehr unterschiedlich. Daher wird in der Improver-Komponente, die die Ergebnisse der verwendeten OCR entgegennimmt, das Konzept des Constraint2.1 Programming (CP) [4] zur Kontrolle und Verbesserung der OCR-Ergebnisse eines Verbundes benutzt.
Die OCR liefert wie oben beschrieben (s. Abschnitt 2.2.4.2) einen OCR-Graphen mit den möglichen Ergebnissen. Für eine Aussage über die Erkennungsqualität kann man sich jedoch nicht auf diese Ergebnisse verlassen. Einen bessere Aussage lässt sich machen, wenn man Wissen über den Kontext eines Dokumentes ausnutzt. Eine Arztrechnung etwa enthält mit sehr grosser Wahrscheinlichkeit die Patientendaten, eine oder mehrere Diagnosen und eine Tabelle mit den abzurechnenden Arzttätigkeiten sowie die Summe aller Kosten. Hier kennst man die GOÄ (Gebührenordnung Ärzte), die die Kostenschlüssel und die erlaubten Kombinationen u.ä. festlegt. Man kann über ein mathematisches Constraint die Einzelbeträge und dann die Summe prüfen und gegebenenfalls korrigieren. Eine andere Möglichkeit, CP zu nutzen, ist die Benutzung von Datenbanken. Hier werden die Datenbankeinträge als Relationen zwischen den entsprechenden Feldern angesehen. Bei einer Adresse beispielsweise kann das OCR-Ergebnis mit einer Kundendatenbank abgeglichen werden, oder der Ort mit der Postleitzahl. Es lässt sich zwar nicht immer ein eindeutiges Ergebnis finden, doch mit einer Heuristik wird das wahrscheinlichste Ergebnis ausgewählt.
Hier zeigt sich wieder ein Problem bei der Festlegung der Ground-Truth: Bei dem obigen Beispiel mit einer Arztrechnung könnte ein Fehler in dem Originaldokument vorhanden sein, etwa ein Rechenfehler. Hier ist die Frage zu stellen, welche Werte für die Grund-Truth zu wählen sind, denn man hat in diesem Beispiel zwei Möglichkeiten. Erstens kann man einen Ansatz verfolgen, der eine buchstäbliche Genauigkeit der Erkennung voraussetzt, also ist der Fehler ``korrekt'' und wird als Ground-Truth angesehen. Andererseits kann man festlegen, dass das was gemeint war, also die korrekte Tabelle, die Ground-Truth sein soll. Da der Improver erheblich bessere Erkennungsraten liefert als eine reine OCR-Erkennung, und da es das Ziel ist, das gesamte System zu optimieren, wird im folgenden von letzteren Ansatz ausgegangen.
Der Verifier dient im Rahmen dieser Arbeit zur Erfassung der Ground-Truth. Jedoch ist es nicht immer sinnvoll, alle möglichen Verfahren und Komponenten zu testen. Beispielsweise ist sie Verdrehung des Bildes nur schwer als Ground-Truth festzulegen, da die Auswirkung einer kleinen Abweichung von der Ground-Truth nicht unbedingt grössere Auswirkungen auf die Qualität haben muss. Dies kann jedoch nur im Rahmen der Fähigkeiten des Verifier geschehen. Da der Verifier z.Zt. beispielsweise keine Änderung der Skalierung oder Verdrehung (Skew) des Seitenbildes eines Dokumentes erlaubt, können diese Daten nur manuell geändert werden bzw. müssten durch ein spezielles Programm erstellt werden. Für diese Arbeit wird deshalb davon ausgegangen, dass nur solche Daten getestet werden sollen, die auch im Verifier korrigierbar sind.
In diesem Kapitel wird der Stand der Benchmarktechnik anhand der Literatur aufgezeigt.
Unter Benchmark versteht man die Bewertung der Performance3.1 eines Softwaresystems.
Bei Dokumentenanalysesystemen (DAS) ist bisher insbesondere die Performance der OCR untersucht worden. Inzwischen hat sich das Interesse der Forschung auch auf die Segmentierung (Zoning) und Bildverarbeitung erweitert (bspw. [22,16,8,12,11,10,18,13,1,15,17,19]). Ein Dokumentenanalysesystem besteht dabei gewöhnlich aus Komponenten zur Bildverarbeitung, Erkennung und Auswertung.
Benchmarking ist aus verschiedenen Gründen wichtig:
Im Allgemeinen besteht ein Benchmark aus Eingabedaten, einem oder mehreren Systemen, einer Bewertungsfunktion (assessment function) und einer Auswertungsfunktion (evaluation function) [22].
Es folgt eine kurze Beschreibung dieser Bestandteile:
Das Konzept beinhaltet, dass jedem realen System Sys ein ideales System IdSys zugeordnet wird. IdSys löst das gestellte Problem optimal. Jede Verbesserung des realen Systems bringt die Systemausgabe somit näher an die optimale Systemausgabe, also die Ground-Truth heran.
Analog zum idealen System definiert man eine ideale Bewertungsfunktion, die die Systemausgabe in der gewünschten Weise berechnet.Eine reale Bewertung dagegen kann den korrekten Bewertungswert nur abschätzen, so dass Ungenauigkeiten entstehen.
Nach den Definitionen in Abschnitt 3.2.1 und 3.2.2 ist die Ground-Truth jetzt als die optimale Ausgabe eines idealen Systems anzusehen. Bei der Definition stellt sich also die Frage, zu was Ground-Truth optimal sein soll. Beispielsweise könnte ein Handschriftexperten 'A' und eine anderer 'H' erkennen. Welche Antwort ist hier optimal? Ground-Truth muss also sorgfältig ausgewählt werden.
Ohne Beschränkung der Allgemeinheit kann man festlegen, dass die Bewertungsfunktion eine Kostenfunktion sein soll, die immer positiv ist und bessere Ergebnisse immer kleinere Werte ergeben. Ist die Systemausgabe äquivalent zur Ground-Truth ergibt die Bewertungsfunktion Null.
In diesem Abschnitt beschränken wir nun die vorigen Konzepte auf den Bereich der Dokumentenanalyse. Grundsätzlich hat man auch hier die gleichen Ziele wie bei Benchmarking im Allgemeinen. Man möchte in der Kette der Module, die ein System bilden, das schwächste Glied identifizieren oder einfach das System als Ganzes testen.
Tests für das ganze System werden schon längere Zeit durchgeführt. Allgemein akzeptierte Tests hierfür werden von Institutionen wie NIST3.2 [6] und ISRI3.3 [21] durchgeführt.
Problematisch ist bei der Dokumentenanalyse vor allem die Vorverarbeitung, da sich dort eine ideale Bewertung nur schwer zu finden ist, oft subjektiv ist und es bisher keinen Standard für die Beschreibung von Datenmengen gibt.
Benchmarking wird erst möglich, wenn man die Ground-Truth kennt. Wir müssen die Ground-Truth aber erst erzeugen. Man kann eine Prozedur definieren, die ähnlich wie das Benchmarking selbst funktioniert: Wir müssen die Eingabedaten, das System oder Subsystem, die Bewertung und vielleicht die Auswertung kennen. Die ideale Bewertungsfunktion zu finden ist jedoch sehr schwer, wenn nicht unmöglich.
Folgende Ansätze werden in der Literatur für die Bewertungsfunktion angegeben:
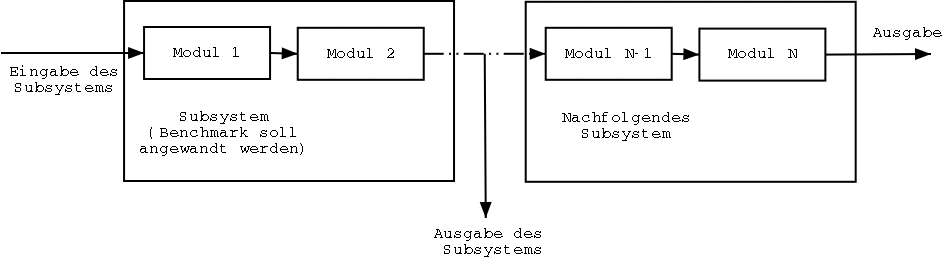
Beim zweiten Ansatz wird die Bewertungsfunktion durch die nachfolgenden Subsysteme ersetzt. Dies geschieht solange, bis man Ground-Truth wieder einfach definieren kann.
In Abbildung 3.2 beispielsweise sind die Module 1 und Module 2 zu untersuchen, die darauf folgenden Module 3 bis N repräsentieren das nachfolgende Subsystem, also die Bewertungsfunktion. Dieser Ansatz wird häufig verwendet, z.B. bei Lam und Suen [10], bei Kanai, Rice und Nartker [8], bei Trier und Jain [11] und bei Lee, Park und Tang [19].Der dritte Ansatz ersetzt die ideale Bewertung durch einen Vergleich mit Ground-Truth. In diesem Fall muss man Ground-Truth explizit kennen, dies können auch synthetische Daten sein. Man kann Ground-Truth bei realen Daten auch durch Experten erzeugen lassen, dies ähnelt dem ersten Ansatz. Auch hier ist die Subjektivität des Experten und die Schwierigkeit Regeln zu definieren, die objektive Ground-Truth ergeben, problematisch. Andererseits erzeugen reale Daten die aussagekräftigsten Ergebnisse.
Kennt man die Systemausgabe und die Ground-Truth, kann ein Abstand einfach berechnet werden, um die Qualität der Ausgabe im Bezug zur Ground-Truth auszuwerten.
Benutzt wurde dieser Ansatz von Haralick, Jaishima und Dori [16], von Lee, Lam und Suen [18], von Palmer, Dabis und Kittler [13], von Yanikoglu und Vincent [1], von Randriamasy [15] und von Randriamasy und Vincent [17].
Alle diese Ansätze haben unterschiedliche Probleme. Wegen der Abhängigkeit der Ergebnisse von der Bewertungsfunktion und weil diese nur eine Annäherung der idealen Bewertungsfunktion ist, muß man sich der Fehler und ihrer Auswirkungen auf die Ergebnisse bewusst sein. Insbesondere da man oft nur die Schnittstellen kennt oder die Bewertung in den nachfolgenden Subsystemen durchführt, ist der Ursprung des eigentlichen Fehlers oft nur schwer zu finden.
Noch schwerwiegender ist die Tatsache, dass die korrekte Ground-Truth selbst fehlerhaft sein kann, weil sie nicht exakt bestimmt werden kann. Dies erschwert die Fehlersuche noch weiter.
Die Erhebung von Ground-Truth für die OCR eines Systems ist noch relativ einfach, da sie gut erforscht ist und man nur die entsprechenden Buchstaben vergleichen muss.
Doch schon die Vorverarbeitung und die Nachbearbeitung sind noch nicht gut erforscht. Die Schwierigkeit bei der Ground-Truth-Erhebung beispielsweise von Vorverarbeitungsschritten ist, dass oft kein genauer Wert angegeben werden kann. Will man z.B. ein Skew-Detection3.4-Modul testen, so kann man eben keinen genauen Wert für die korrekte Verdrehung einer Seite angeben, weil sich diese normalerweise in einem gewissen Intervall bewegt, das aber nicht konstant sein muss. Man muss daher entweder einen Mittelwert angeben oder ein grosses Intervall.
Prinzipiell lassen sich drei Möglichkeit identifizieren, Ground-Truth zu bestimmen [22]:
Eine weitere Möglichkeit ist es, eine Person mit der Bestimmung der Ground-Truth zu beauftragen. Lee, Lam und Suen [18] definieren Ground-Truth durch den Einsatz von fünf Experten und fünf Nichtexperten, die eine ideale Segmentierung einzeichnen sollen. Von diesen Bildern wird eine Art Durchschnitt der Segmentierung berechnet.
Die dritte Möglichkeit ist eine iterative Annäherung. Die Idee ist es, die Bewertungsfunktion mit Eingabedaten zu füttern und ihre Nähe zur Ground-Truth einzuschätzen, indem man die Ausgabe betrachtet. Diese Ausgabe wird als Referenz für die Veränderung der Eingabedaten benutzt, die wiederum wie oben beschrieben behandelt werden. Ground-Truth hat man gefunden, wenn die Bewertungsfunktion Null wird. Die Bewertungsfunktion kann auch hier ein Mensch oder ein nachfolgendes System sein.
Die wichtigste Erkenntnis dieses Abschnittes ist es, dass die Ground-Truth erheblich von der benutzten Bewertungsfunktion abhängt.
Das Ziel dieser Projektarbeit ist es, ein Programm für Benchmarking zu entwickeln und zu implementieren. Dabei sollen folgende Bedingungen gelten:
Der Ansatz für das Statistikprogramm läßt die Erhebung aller während der Analyse erhobenen Daten zwar grundsätzlich zu, es sprechen jedoch verschiedene Gründe dagegen:
In der Praxis hat sich gezeigt, dass die mit dem Verifier erfassbaren Daten im Allgemeinen sehr gut zur optimierung des Systems geeignet sind.
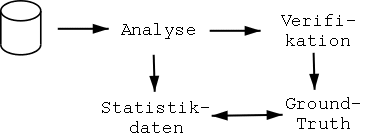
Sowohl die Ground-Truth-Objekte als auch die damit zu vergleichenden Objekte (im folgenden Vergleichsobjekte genannt) werden von der Extraktion erzeugt.
Die Extraktion erhält vom Programm die verfügbaren Bildstapel, durchläuft die Dokumente dieser Bildstapel und erzeugt die entsprechenden Dokumentenobjekte. Für jedes Dokument werden dann die Felder und die Seiten durchlaufen und wiederum die entsprechenden Statistikobjekte erzeugt. Eine solche Liste von Dokumentenobjekten wird für jeden Bildstapel erzeugt. Das Programm speichert dann die Statistikdaten stapelweise in Textdateien. Der Name dieser Textdateien setzt sich dabei aus dem Präfix ``GT'' für Ground-Truth-Daten bzw. ``Cmp'' für Vergleichsdaten, der Identifikation des Bildstapel und der Dateiendung ``.txt'' zusammen. Beispielsweise würden die Ground-Truth-Daten eines Bildstapels ``TestDocs'' in der Datei ``GTTestDocs.txt'' abgespeichert. Der Präfix ist für das Wiedereinlesen der Statistikdaten insofern wichtig, als dass das Programm mit dem Muster ``GT*.txt'' bzw. ``Cmp*.txt'' nach Daten für die Bildstapel sucht.
Zur Erstellung der Ground-Truth wird für die gewünschten Dokumente ein Analysevorgang durchgeführt. Dabei ist zu beachten, dass die Dokumente zu den gleichen Bildstapeln zusammengefasst werden, wie sie später analysiert werden, da das Benchmarkprogramm nur Dokumente in gleichen Bildstapel vergleicht.
Desweiteren müssen die Bildidentifikationen der Dokumente gleich sein, da das Programm diese zur Zuordnung der einzelnen Seiten zueinander benutzt.
Ist die Analyse erfolgt, müssen die Daten mit dem Verifier überprüft werden. Hier ist besondere Sorgfalt nötig, da die hier erzeugten Daten bei späteren Vergleichen als die wahren Feldwerte angesehen werden. Falsche Werte in der Ground-Truth führen also bei späteren Vergleichen zu falschen Ergebnissen (s. Abschnitt 4.4).
Hier hat sich das Vier-Augen-Prinzip bewährt: Die Verifikation wird von zwei Personen durchgeführt und die Ergebnisse miteinander verglichen. Die Unterschiedene werden dann von einer dritten Perosn aufgelöst und diese Daten als Ground-Truth übernommen. Diese Methode entspricht der oben beschriebenen (s. Abschnitte 3.3.2).
Die vom Verifier in der Systemdatenbank abgelegten Daten werden jetzt vom Statistiktool eingelesen und wie oben beschrieben (s. Abschnitt 4.3.1) in das eigene Datenformat umgewandelt. Werte, die der Verifier nicht ändern kann, die aber durch den Analyser nicht korrekt erzeugt wurden, müssen hier von Hand nachkorrigiert werden.
Zum Vergleich der Ground-Truth mit Analyseergebnissen werden die Analyseergebnisse direkt aus dem Analyser vom Programm eingelesen und in das eigene Format umgewandelt.
Jetzt können Ground-Truth und Analyseergebnisse miteinander verglichen werden (s. Abschnitt 5.4.1).
Das Programm erzeugt nun die Dateien mit den Ergebnissen und stellt sie dar (s. Abbildung 5.7).
Im folgenden Abschnitt wird häufig von ``Dokumentenvergleich'' die Rede sein. Gemeint ist nicht der Vergleich zwischen verschiedenen Dokumenten, sondern immer ein Vergleich zwischen Ground-Truth und Analyseergebnis eines Dokumentes.
Um falsche Vergleichsergebnisse zu vermeiden, wurde eine ``defensive'' Strategie gewählt. Dies bedeutet, dass es vorgezogen wurde, einen Vergleich abzubrechen, wenn eine unsichere Situation entsteht. Beispielsweise würde eine Weiterführung des Vergleichs bei falscher Klassifikation zu viele falsche Felder ergeben. Dies würde die Fehlerstatistik unnötig verschlechtern und den Fehlergrund verschleiern. Dies ist entspricht der Forderung von Märgner, Karcher und Pawlowski [22] aus Abschnitt 3.3.1 darauf zu achten, dass die Fehlerursache nicht nur durch die reinen Daten überdeckt werden sollen.
Damit die Klassifikation eines Dokumentes mit seiner Ground-Truth übereinstimmt, müssen die folgenden Bedingungen gelten:
Der Vergleich von Feldern besteht aus zwei Teilen, dem OCR-Vergleich und dem Vergleich des Analyseergebnisses.
Der OCR-Vergleich vergleicht das Ergebnis der OCR mit der Ground-Truth. Da die Ground-Truth jedoch auf einen Vergleich mit dem Analyseergebnis, also dem Ergebnis des Improvers, abgestimmt ist, ist die Aussage dieses Vergleichs eingeschränkt. Betrachten wir im Folgenden den Vergleich eines Betragsfeldes und nehmen an, dass auf dem Original ``120,00'' steht. Um das gesetzte Ziel, das System zu optimieren, erreichen zu können, muss als Ground-Truth für dieses Feld ``120.00'' angenommen werden. Dies ist wegen des Improvers nötig, der automatisch Betragswerte in die anglikanische Notation, also ein Dezimalpunkt statt eines Dezimalkommas, konvertiert.
Der wichtigere Vergleich für die Optimierung ist der zwischen Ground-Truth und Analyseergebnis.
Beide Vergleiche werden durch den gleichen Algorithmus durchgeführt. Dabei kommt das zu definierende Ähnlichkeitsmaß (s. Abschnitt 5.2) zum Einsatz.
Untersucht werden hierbei normale Felder und Felder aus Tabellen (s. nächsten Abschnitt).
Zuerst wird die Dimension der Tabelle, d.h. die Anzahl der Zeilen und Spalten, verglichen. Sind die Dimensionen bei Analyseergebnis und Ground-Truth gleich, so wird davon ausgegangen, dass bei der Analyse des Dokumentes die Tabelle korrekt erkannt wurde. In diesem Fall werden die einzelnen Tabellenzellen direkt verglichen, also die Zelle an der Position (i,j) aus dem Analyseergebnis wird mit der Zelle an der gleichen Position in der Ground-Truth verglichen. Dabei wird wie im vorherigen Abschnitt beschrieben vorgangen.
Sind die Dimensionen nicht gleich, wird versucht mit Hilfe des noch zu definierenden Ähnlichkeitsmasses für Tabellen (s. Abschnitt 5.3) ähnliche Tabellenzeilen zu identifizieren und dann die enthaltenen Zellen zu vergleichen. Dies wird jedoch nur durchgeführt, wenn die Anzahl des Spalten gleich ist. Ansonsten wird der Vergleich für diese Tabelle abgebrochen.
Dieser Vergleich dient nur der Information, ob die Dimension der untersuchten Tabelle von der Ground-Truth abweicht. Dies ist nur insofern wichtig, als dass diese Information deutlich macht, wie die Auswahl des Vergleichs der Tabelle, wie im vorherigen Abschnitt beschrieben, zustande kommt.
Sowohl die Ground-Truth-Objekte als auch die damit zu vergleichenden Objekte (in folgenden Vergleichsobjekte genannt), werden von der Extraktion, implementiert in der Klasse statExtraction, wie in Abschnitt 4.3.1 beschrieben, erzeugt.
Die Daten werden in der Textdatei wie folgt gespeichert:
Beim Einlesen wird die gesamte Datei zeilenweise eingelesen und analysiert. Dabei wird ein temporärer Datenbaum erzeugt (s. Abbildung 5.1).
Dieser ermöglicht es die Objekte so zu erzeugen, dass fehlende Attribute in der Datei trotzdem eingelesen werden können, da die Blätter des Baumes als Attribute der übergeordneten Knoten angesehen werden. Beim Einlesen eines Attributes werden dessen Name sowie der Name des dazugehörigen Objekts als Suchkriterien angegeben. Ist das Attribut im Baum nicht vorhanden, wird ein Standardwert für den Datentyp des Attributs zurückgegeben. Überflüssige Attribute werden so ignoriert. Somit ist das Programm nur beim Einlesen der Daten aus den Datenbanken auf deren Versionsstand des Binärformats angewiesen. Dies vereinfacht die Weiterentwicklung des Statistiktools sehr, da nicht bei jeder Änderung der Datenstrukturen die Ground-Truth von neuem erezugt werden muss. Hierbei ist jedoch zu beachten, dass die Attribute ``ClassId'', ``Name'' und ``isGT'' vorhanden sein müssen, um die korrekte Erzeugung der Objekte zu gewährleisten. Das folgende Beispiel zeigt ein minimales Dokument:
Dokument.Name=Dokument
Dokument.isGT=1
Das Format ist zwar unabhängig vom Vorhandensein bestimmter Attribute oder Werte eines Objektes, jedoch können Änderung der Bedeutung von Attributen nicht durch das Programm abgefangen werden. Dazu muss jeweils ein Konvertierungsprogramm erstellt werden, dass ältere Daten in die gewünschte Form bringt. Eine andere Möglichkeit wäre es das Analyseprogramm so zu ändern, dass es die verschiedenen Bedeutungen erkennt und entsprechend reagiert.
Dieses Maß wurde nach dem russischen Wissenschaftler Wladimir Levenshtein benannt, der den Algorithmus 1965 entwickelt hatte [7].
Das Levenshtein-Maß, auch Editierabstand genannt, wird überall dort gebraucht, wo es nicht ausreicht zu wissen, ob zwei Worte5.1 gleich sind. Beispiele für Anwendungen sind Spracherkennung, DNA-Analyse und Rechtschreibprüfung [7,3,23,14,9].
Der Levenshtein-Algorithmus liefert einen Wert zurück, der ein Maß der Ähnlichkeit zweier Zeichenketten angibt. Die Definition eines Maßes verlangt eine Normierung, so dass hier zunächst der absolute Abstand der beiden Zeichenketten bestimmt und durch den größerern Wert der beiden Zeichenkettenlängen geteilt wird. Dies ergibt den relativen Abstand d der Zeichenketten. Die Ähnlichkeit s ist dann s=1-d. Der absolute Abstand zweier Zeichenketten ist hier der kürzeste Weg, der benötigt wird, um durch die Operationen Einfügen, Löschen und Vertauschen mit den geringsten Kosten von der ersten Zeichenkette zu zweiten Zeichenkette zu gelangen. Die Operationen werden dabei gewichtet, d.h. die Kosten der Operation werden berücksichtigt. Beispielsweise könnte das Einfügen günstiger als Löschen sein, also könnten die Kosten für Einfügen 1 sein und für Löschen 2.
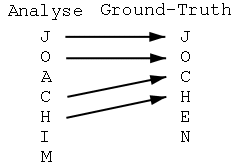
Dies soll am folgenden Beispiel verdeutlicht werden: Enthalte s1 die Zeichenkette JOCHEN und s2 JOACHIM. Wir nehmen bei diesem Beispiel der Einfachheit an, dass die Kosten für alle operationen gleich 1 ist. Der absolute Abstand kann dann aus der Tabelle 5.1 an der rechten, unteren Ecke abgelesen werden und ist 3.
|
Dieses Ergebnis wird durch 7 geteilt und ergibt eine Ähnlichkeit von s=1-(3/)=1-0,43=0,57. Man erkennt anhand der Tabelle 5.2, dass es durchaus mehrere Möglichkeiten gibt, einen kürzesten Weg mit den geringsten Kosten zu finden.
|
Das Ergebnis des Levenshtein-Maß selbst trotz der Möglichkeit von mehreren kürzesten Pfaden eindeutig, so dass die Auswahl des Pfades keine Auswirkung auf das Ergebnis des Algorithmus hat.
Im vorhergehenden Abschnitt wurde eine Levenshtein-Maß auf Zeichenketten angegeben. Man kann nun analog dazu einen Levenshtein auf Listen von Zeichenketten und Listen davon (also Tabellen) definieren, denn eine Zeichenkette ist ja eine Liste von Zeichen. Dies führte zu einer Implementierung des Levenshtein-Algorithmus in einer C++-Templateklasse, die dann entsprechend für Zeichenketten, Listen und Tabellen instantiiert wurde. Zur Berechnung der Distanz zwischen zwei Elementen wird rekursiv das Levenshtein-Maß für den entsprechenden Elementtyp aufgerufen. Um die Klasse flexibel zu halten, werden auf einem Stack die Parameter für jedes Levenshtein-Maß plaziert. Neben den Kosten der Editieroperationen kann noch angegeben werden, ob bei der Distanz zweier Elemente auf Gleichheit geprüft werden soll oder das Levenshtein-Maß des Elementtyps herangezogen werden soll. Desweiteren ist es möglich, für Zeichenketten eine Vertauschungsmatrix anzugeben. In dieser Matrix stehen die Ähnlichkeiten von Zeichen zueinander. Ein Zeichen hat zu sich selbst grundsätzlich die Ähnlichkeit 1. Soll z.B. festgelegt werden, dass ein Komma und ein Punkt gleich sein sollen, dann gibt man ihnen in der Vartauschungsmatrix jeweils einen Wert von 1.
Bei der Erkennung von Tabellen kommt es vor, dass Zeilen falsch getrennt oder nicht erkannt werden. D.h. Zeilen sind im Analyseergebnis gegenüber der Ground-Truth zu viel oder fehlen. Um dennoch möglichst viele Zeilen des Analyseergebnisses mit der Ground-Truth vergleichen zu können, wird das oben beschriebene Levenshtein-Maß auf Tabellen angewandt. Im folgenden wird erleichternd davon ausgegangen, dass Überkreuzung von gleichen Zeilen nicht vorkommt, sondern das Tabellenzeilen, auch bei Fehlen oder Einfügen neuer Zeilen in der richtigen Reihenfolge auftreten. Ein Vorkommen von Überkreuzung wird als so kritischer Fehler der Tabellenerkennung angesehen, so dass der Bewertungsfehler als nicht kritisch gewertet wird.
Wichtig bei der Anwendung in diesem Kontext ist es, dass das Gewicht für Vertauschung größer oder gleich der Summe der Gewichte von Einfügen und Löschen eingestellt wird. Wird dies nicht beachtet, können die zusammen passenden Tabellenzeilen gefunden werden. Dies lässt sich durch die Tatsache erklären, dass der Algorithmus stets einen kürzesten gewichteten Weg sucht. Eine Vertauschungsoperation, die äquivalent einer gleichzeitigen Löschung und Einfügung ist, würde bei gleicher Gewichtung immer einen kürzeren Weg als Einfügen oder Löschen angeben. Dies führt jedoch bei dem beschriebenen Tabellenlevenshtein dazu, dass unähnliche Zeilen einander zugeordnet werden, weil sie ja vertauschbar sind.
Um die passenden Zeilen zu finden, wird ein kürzester Pfad ermittelt. Dieser wird rückwärts von der Zelle rechts unten in der Distanzmatrix nach links oben verfolgt. Es gibt nun in diesem Pfad drei Schritte, die auftreten können:
Zur Verdeutlichung betrachten wir nochmal die Tabelle 5.1. Für dieses Beispiel sollen die einzelnen Buchstaben Tabellenzeilen darstellen, wobei gleiche Buchstaben gleiche Zeilen bedeuten. Weiter sei ``JOCHEN'' die Ground-Truth und ``JOACHIM'' das Analyseergebis. In Abbildung 5.2 kann das Zuordnungsergebnis abgelesen werden. Man sieht, dass der Algorithmus die Zeilen 'J', 'O', 'C' und 'H' einander zuordnen konnte. Die Zeilen 'E' und 'N' der Ground-Truth finden sich jedoch nicht im Analyseergebnis. Die Analyse hat ausserdem die Zeilen 'I' und 'M' erzeugt, die jedoch in der Ground-Truth nicht zu finden sind.
Die Klasse statCompare ist die zentrale Klasse der Vergleiche und ruft die definierten statCompare-Objekte dokumentenweise auf.
statCompare ruft die zu den Objektklassen korrespondierenden Vergleichsklassen dokumentenweise auf. Die Ergebnisse der Vergleiche werden von statCompare gesammelt und an das Programm weitergegeben. Bei Nichterfolg eines Vergleichs werden abhängige Vergleiche nicht ausgeführt. So macht es z.B. keinen Sinn einen Vergleich der OCR-Ergebnisse durchzuführen, wenn die Klassifikation des Dokumentes nicht stimmt, da der Analyser häufig aufgrund der Dokumentenklassifikation die Bereiche der Seite auswählt, in denen die OCR Zeichen suchen soll.
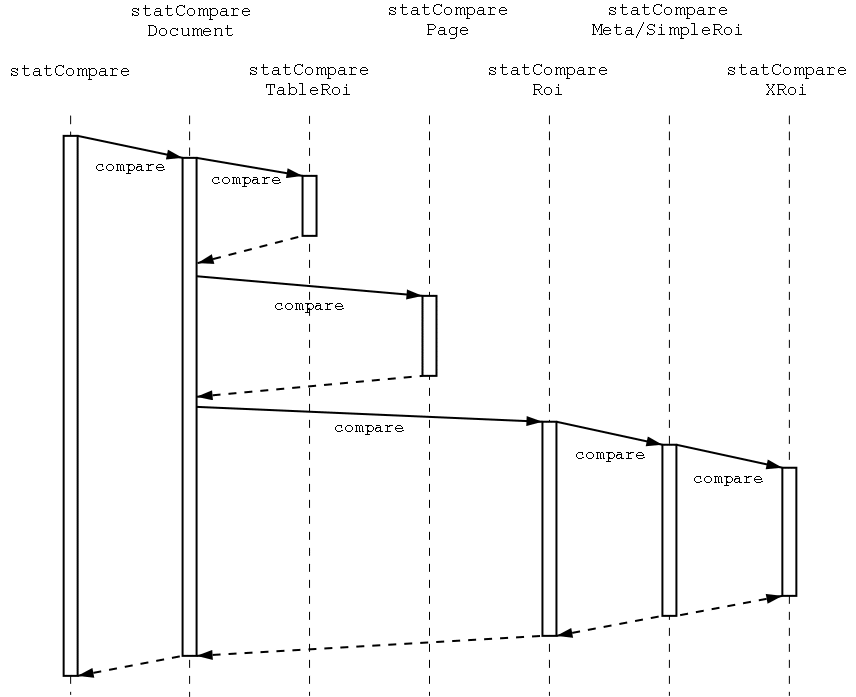
Das Programm übergibt die Dokumente für Ground-Truth und Analyseergebnis in einem Bildstapel an statCompare. Diese Klasse versucht anhand der Bildidentifikationen die einzelnen Seiten in Ground-Truth und Analyseergebnis einander zu zuordnen. Dies ist nötig, um Seitenzuordnungsfehler zu erkennen. Nur Dokumente, deren Seiten zueinander passen, werden weiter verglichen. Jetzt ruft statCompare für jedes Dokument statCompareDocument auf (s. Abbildung 5.3).
statCompareDocument ruft seinerseits statCompareTableRoi für eine vorhandene Tabelle auf. Danach wird für jede Seite statComparePage aufgerufen. Hier werden einieg Informationen über seiten gesammelt. Als Nächstes wird für jedes Feld entsprechend des Feldtyps entweder statCompareMetaRoi oder statCompareSimpleRoi aufgerufen. Nach Ermittlung allgemeiner Daten wird die entsprechende Vergleichsklasse aufgerufen, z.B. für ein Textfeld statCompareTextRoi. Alle von einer Vergleichsklasse erzeugten Ergebnisse werden von der aufrufenden Klasse gesammelt und ebebfalls an den eigenen Aufrufer weitergereicht, bis alle Vergleichsergebnisse zu statCompare gelangen.
Zwar werden alle Vergleichsklassen aufgerufen, aber nur wenige erezugen z.Zt. tatsächlich Vergleichsergebnisse:
In diesem Abschnitt werden die einzelnen Vergleiche detailierter beschrieben. Die Begriffe ``Ground-Truth'' und ``Analyseergebnis'' beziehen sich in diesem Abschnitt nur auf das jeweils untersuchte Dokument.
statCompareDocument überprüft die korrekte Klassifikation des analysierten Dokumentes und führt nur weitere Vergleiche auf diesem Dokument durch, wenn die Klassifikation korrekt ist. Die Klassifikation ist genau dann korrekt, wenn folgende Bedingungen gelten:
statCompareTableRoi überprüft nur die korrekten Dimensionen der Tabellen des Analyseergebnisses, d.h. ob sowohl die Anzahl der Spalten als auch die Anzahl der Zeilen mit denen der Ground-Truth überein stimmen.
Im ersten Schritt wird die auf dieser Seite befindliche Tabelle überprüft.
statCompareRoi zeichnet den Namen und den Feldtyp von Ground-Truth und Analyseergebnis des gerade bearbeiteten Feldes auf. Danach wird je nach Feldtyp statCompareMetaRoi oder statCompareSimpleRoi aufgerufen. statCompareMetaRoi wiederum ruft nur die dem Feldtyp entsprechende Vergleichsoperation auf (ausgenommen statCompareTableRoi). Diese Feldtypen erzeugen zur Zeit jedoch keine Vergleichsergebnisse.
statCompareSimpleRoi macht zwei Levenshtein-Vergleiche, wobei nur beim zweiten eine Vertauschungsmatrix (s. Abschnitt 5.3) benutzt wird.
In diesem Abschnitt wird die Benutzeroberfläche des beschriebenen Programms erläutert. Das Programm wurde mit dem GUI-Tollkit Qt der norwegischen Firma Trolltech erstellt.
Das Hauptfenster hat verschiedene Menüs, eine Statuszeile und einen Bereich in der Mitte des Hauptfensters, der Unterfenster enthält. Das Verhalten der Unterfenster ist ähnlich dem des MDI-Paradigmas (Multiple Document Interface).
Nach dem Start zeigt das Programm den Einstellungsdialog, damit der Benutzer die eingestellten Pfade überprüfen kann. Der Einstellungsdialog besteht aus vier Seiten, die über je eine Auswahllasche ausgewählt werden kann.
Die erste Seite enthält einige Informationen über den Zweck des Dialogs.
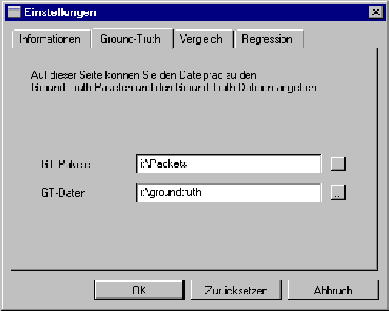
Die nächste Seite (s. Abbildung 5.4) enthält die Einstellungen für die Ground-Truth-Daten. Dabei handelt es sich um die Pfade zu den Quellpaketen und zu den Ground-Truth-Daten.
Die dritte Seite (s. Abbildung 5.5) enthält die Einstellungen für die Vergleichsdaten. Die einzustellenden Daten sind die Pfade zu den Quellpaketen und zu den Vergleichsdaten.
Wenn das Programm eine Aktion durchführt, wird dem Benutzer der Fortschritt (s. Abbildung 5.6) angezeigt, um ihm auch bei längeren Warten auf dem Laufenden zu halten.
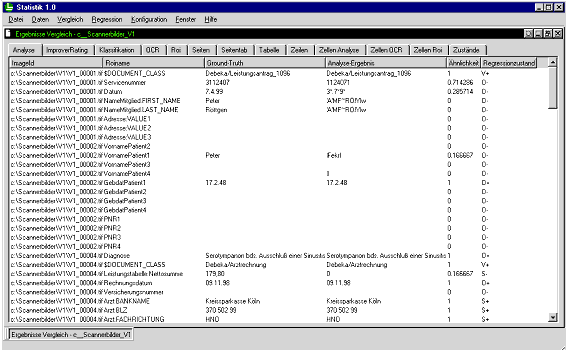
Die Ergebnisanzeige (s. Abbildung 5.7) enthält die Ergebnisse eines Vergleichs (s. Abschnitte 4.4 und 5.3). Dabei werden die einzelnen Ergebnisse in jeweils einer eigenen Seite angezeigt und in einer Tabelle organisiert.
Das in dieser Arbeit beschriebene Verfahren zur Einschätzung der Erkennungsqualität des Dokumentenanalysesystems hat sich schon während der Entwicklung bewährt. So war es zum Beispiel für den Vertrieb einfacher, gegenüber Kunden Aussagen über Erkennungsraten des Systems zu machen.
Bei allen möglichen Anwendungen ist es wichtig, verlässliche und objektive nachprüfende Daten zu erhalten. Dies alles leistet das vorgestellte Verfahren.
Gleichzeitig zeigte sich, dass der Ansatz, von vorne herein alle denkbaren Daten zu erheben, aber diese nicht zu nutzen, nicht trägt. Dieses zeigte sich insbesondere bei der Verarbeitungsgeschwindigkeit, die aufgrund der Menge der Objekte, die jedoch letztlich nicht gebraucht wurden, sehr gesenkt wurde.
Durch die Nachbildung der Systemobjekte wurde die Pflege des Programms erschwert, da jede Änderung des Objektsystems eine Änderung in den Algorithmen nach sich zog.
Insgesamt zeigte sich, dass eine Vereinfachung des Objektsystems und der Eingabedaten nötig ist, um die Weiterentwicklung und Benutzbarkeit des Programmes zu vereinfachen. Jedoch kann dabei der Kern der Vergleichsalgorithmen erhalten bleiben.
Bei den folgenden Implementationsdetails wird folgendes Schema angewandt:
Die folgenden Typen werden durch typedef erzeugt zur Abkürzung
und Übersichtlichkeit.
| Name | Typ |
| statDocumentPtr | daPointer<statDocument> |
| statPagePtr | daPointer<statPage> |
| statRoiPtr | daPointer<statRoi> |
| statTableRoiPtr | daPointer<statTableRoi> |
| statPageList | list<daPointer<statPage> > |
| statRoiList | list<daPointer<statRoi> > |
| ideeStringList | list<ideeString> |
| ideeStringVec | vector<ideeString> |
| ideeStringField | vector<vector<ideeString> > |
| statStreamFunc | statAsciiDb& (*func)(statAsciiDb&) |
| statManipFunc | statAsciiDb& (*func)(statAsciiDb&, const ideeString&) |
| ideeStringPairList | list<pair<ideeString, ideeString> > |
| statNode | ideeTreeNode<statNodeObj> |
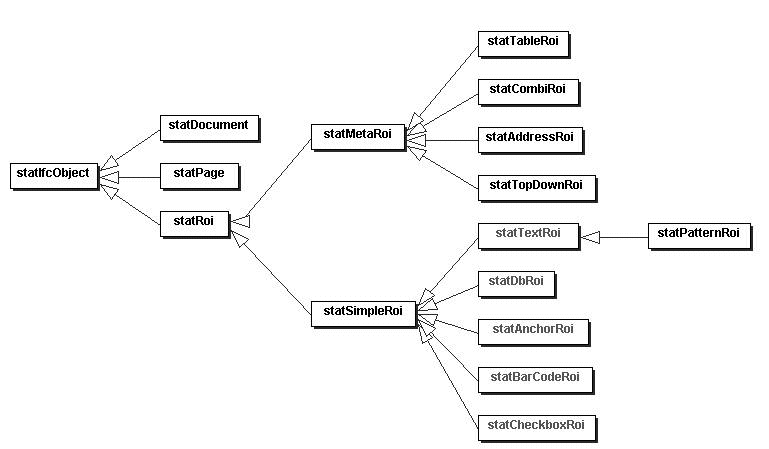
Die Statistikobjekte enthalten die notwendigen Statistikinformationen aus den Objekten der Klassenhierachie von modIdeeInterface (s. Abbildung A.1).
Die Klasse statIfcObject ist die Basisklasse für alle Statistikobjekte.
| Name | Datentyp | Beschreibung | Zugriff |
| IsGround | bool | Ist IsGround true, dann ist dieses Objekt | rw |
| Ground-Truth. Ansonsten ist das Objekt | |||
| ein Vergleichsobjekt. | |||
| Name | ideeString | Enthält den Namen des Objekts. | rw |
| Name | Beschreibung |
| statIfcObject() | Der Standardkonstruktor |
| statIfcObject(const ifcObject &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen eines Dokumentes.
| Name | Datentyp | Beschreibung | Zugriff |
| Pages | statPageList | Die Liste der Seiten, | r |
| die in diesem Dokument enthalten sind. | |||
| RoiList | statRoiList | Die Liste der Felder, | r |
| die in diesem Dokument enthalten sind. | |||
| DocClass | ideeString | Die Dokumentenklasse dieses Dokuments. | rw |
| Name | Beschreibung |
| statDocument() | Der Standardkonstruktor |
| statDocument(const statDocument &obj) | Der Copy-Konstruktor |
| void addPage(const statPagePtr &page) | Fügt eine neue Seite zu diesem Dokument hinzu. |
| const statPagePtr& | Sucht eine Seite mit dem Namen name und gibt |
| page(const ideeString &name) | die gefundene Seite zurück. Wurde keine |
| entsprechende Seite gefunden, so gibt | |
| die Methode einen NULL-Zeiger zurück. | |
| void addRoi(const statRoiPtr &roi) | Fügt ein neues Feld zu diesem Dokument hinzu. |
| const statRoiPtr& | Sucht ein Feld mit dem Namen name und gibt |
| roi(const ideeString &name) | das gefundene Feld zurück. Wurde kein |
| entsprechendes Feld gefunden, so gibt die | |
| Methode einen NULL-Zeiger zurück. | |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer Seite.
| Name | Datentyp | Beschreibung | Zugriff |
| SkewAngle | float | Der Winkel, mit dem das Originalbild | rw |
| gegenüber der aufrechten Position | |||
| gedreht wurde. | |||
| Movement | daPoint | Die Attribute x und y von daPoint | rw |
| geben die Verschiebung des Originalbildes | |||
| gegenüber der richtigen Position an. | |||
| Scale | float | Der Skalierungsfaktor, mit dem das Original- | rw |
| bild in das Analysebild verwandelt wurde. | |||
| ImageId | ideeString | Der eindeutiger Name des Seitenbildes, | rw |
| wie er durch das Bildarchivierungssystem | |||
| erzeugt wurde. | |||
| RoiList | ideeStringList | Die Liste der Namen der Felder, | r |
| die auf dieser Seite enthalten sind. | |||
| TableCells | ideeStringList | Die Liste der Tabellenzellen, | rw |
| die auf dieser Seite enthalten sind. | |||
| Columns | int | Die Anzahl der Tabellenspalten | rw |
| auf dieser Seite. | |||
| Rows | int | Die Anzahl der Tabellenzeilen | rw |
| auf dieser Seite. | |||
| Name | Beschreibung |
| statPage() | Der Standardkonstruktor |
| statPage(const statPage &obj) | Der Copy-Konstruktor |
| void addRoiName(const ideeString &name) | Fügt einen neuen Feldnamen |
| zu dieser Seite hinzu. | |
| void addTableCell(const ideeString &name) | Fügt einen neuen Feldnamen |
| einer Tabellenzellen zu dieser Seite hinzu. | |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen eines Feldes.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statRoi() | Der Standardkonstruktor |
| statRoi(const statRoi &obj) | Der Copy-Konstruktor |
| virtual const bool isMeta() | Gibt true zurück, wenn |
| const | das Feldobjekt ein Meta-Feld repräsentiert. |
| static statRoiPtr | Erzeugt ein Feld, das den Klassentyp |
| createRoi(ideeString classTyp, | classTyp, z.B. TextRoi, |
| ideeString name) | und den Namen name hat. |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer SimpleRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| OcrResult | ideeString | Resultat der OCR. | rw |
| DbMatchResult | ideeString | Resultat des DB-Matches. | rw |
| RegExpResult | ideeString | Resultat der regulären | rw |
| Ausdrücke. | |||
| ProveRestrictionResult | ideeString | Resultat der prüfenden | rw |
| Restriktionskontrolle. | |||
| CorrectRestrictionResult | ideeString | Resultat der korrigierenden | rw |
| Restriktionskontrolle. | |||
| AnalyserResult | ideeString | Resultat des Analyser. | rw |
| VerifierResult | ideeString | Resultat der Verifikation. | rw |
| Creator | ideeString | Wurde diese SimpleRoi aus einer | rw |
| MetaRoi erzeugt, so enthält dieses | |||
| Attribut den Namen dieses Feldes. | |||
| ImproverRating | ifcSimpleRoi | Bewertung des Ergebnisses | rw |
| (mImpRating) | ::ImproverRating | durch den Improver | |
| VerifierAction | ifcSimpleRoi | Aktion, die bei der Verifikation | rw |
| (mVerAction) | ::VerifierAction | durchgeführt wurde. | |
| Name | Beschreibung |
| statSimpleRoi() | Der Standardkonstruktor |
| statSimpleRoi(const statSimpleRoi &obj) | Der Copy-Konstruktor |
| virtual const bool isMeta() | Gibt true zurück. |
| const | |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() const | Liefert den Klassentyp als Zeichenkette |
Diese Klasse repräsentiert die Statistikinformationen einer BarcodeRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statBarcodeRoi() | Der Standardkonstruktor |
| statBarcodeRoi(const statBarcodeRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer CheckboxRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statCheckboxRoi() | Der Standardkonstruktor |
| statCheckboxRoi(const statCheckboxRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer DbRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statDbRoi() | Der Standardkonstruktor |
| statDbRoi(const statDbRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer TextRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statTextRoi() | Der Standardkonstruktor |
| statTextRoi(const statTextRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer PatternRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statPatternRoi() | Der Standardkonstruktor |
| statPatternRoi(const statPatternRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer MetaRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statMetaRoi() | Der Standardkonstruktor |
| statMetaRoi(const statMetaRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Diese Klasse repräsentiert die Statistikinformationen einer AddressRoi.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statAddressRoi() | Der Standardkonstruktor |
| statAddressRoi(const statAddressRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statCombiRoi() | Der Standardkonstruktor |
| statCombiRoi(const statCombiRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
| Name | Datentyp | Beschreibung | Zugriff |
| TableType | ideeString | Der Typ dieser Tabelle. | rw |
| Columns | int | Die Anzahl der Spalten. | rw |
| Rows | int | Die Anzahl der Zeilen. | rw |
| Header | ideeStringList | Die Liste der Spaltenüberschriften. | rw |
| TableCells | ideeStringList | Die Liste der Namen der Tabellenzellen. | rw |
| Name | Beschreibung |
| statTableRoi() | Der Standardkonstruktor |
| statTableRoi(const statSimpleRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statTopDownRoi() | Der Standardkonstruktor |
| statTopDownRoi(const statTopDownRoi &obj) | Der Copy-Konstruktor |
| virtual void write(statAsciiDb &db) | Schreiboperator |
| const | |
| virtual void read(statAsciiDb &db) | Leseoperator |
| virtual const ideeString classTyp() | Liefert den Klassentyp als Zeichenkette |
| const | |
Die genaue Anleitung zum Einsatz von Manipulatoren bei Streams kann [20], Seiten 676-678 entnommen werden.
| Name | Datentyp | Beschreibung | Zugriff |
| Path | ideePath | Der Pfad zur Datei, in die geschrieben oder | r |
| aus der gelesen werden soll. | |||
| Tree | statObjTree* | Der temporäre Baum, der beim Einlesen der | rnc |
| Objekte erzeugt wird. | |||
| ActDoc | ideeString | Der Name des aktuellen Dokuments. | r |
| ActPage | ideeString | Der Name der aktuellen Seite. | r |
| ActRoi | ideeString | Der Name der aktuellen Roi. | r |
| ActAttr | ideeString | Der Name des aktuelen Attributs. | r |
| Stream | fstream | Der Ein- und Ausgabestream auf die | |
| benutzte Datei. | |||
| Writing | bool | Dieses Flag zeigt an, ob der Stream zum | r |
| (mWrite) | Schreiben oder Lesen geöffnet wurde. | ||
| Aborted | bool | Dieses Flag zeigt an, ob die Schreib- | |
| oder Leseoperator abgebrochen wurde. | |||
| Name | Beschreibung |
| statAsciiDb(const ideePath &path, | Der Konstruktor |
| const bool bWrite | |
| Der Destruktor | |
| void open() | Öffnet den Stream. |
| throw(ideeFileOpenError) | |
| void close() | Schliesst den Stream. |
| throw(ideeFileCloseError) | |
| void writeChar(char &value) | Schreibt ein char. |
| throw(ideeFileWriteError) | |
| void writeBool(bool &value) | Schreibt ein bool. |
| throw(ideeFileWriteError) | |
| void writeInt(int &value) | Schreibt ein int. |
| throw(ideeFileWriteError) | |
| void writeULong(ulong &value) | Schreibt ein ulong. |
| throw(ideeFileWriteError) | |
| void writeFloat(float &value) | Schreibt ein float. |
| throw(ideeFileWriteError) | |
| void writeDouble(double &value) | Schreibt ein double. |
| throw(ideeFileWriteError) | |
| void writeString(const char *value) | Schreibt eine C-Zeichenfolge. |
| throw(ideeFileWriteError) | |
| void readChar(char &value) | Liest ein char. |
| throw(ideeFileReadError) | |
| void readBool(bool &value) | Liest ein bool. |
| throw(ideeFileReadError) | |
| void readInt(int &value) | Liest ein int. |
| throw(ideeFileReadError) | |
| void readULong(ulong &value) | Liest ein ulong. |
| throw(ideeFileReadError) | |
| void readFloat(float &value) | Liest ein float. |
| throw(ideeFileReadError) | |
| void readDouble(double &value) | Liest ein double. |
| throw(ideeFileReadError) | |
| void readString(char *value) | Liest eine C-Zeichenfolge. |
| throw(ideeFileReadError) | |
| statAsciiDb& operator« | Dieser Operator erlaubt paramterlose |
| (statStreamFunc func) | Manipulatoren. |
| throw (ideeFileWriteError) | |
| statAsciiDb& operator» | Dieser Operator erlaubt paramterlose |
| (statStreamFunc func) | Manipulatoren. |
| throw (ideeFileReadError) | |
| statAsciiDb& setAttribName | Wird über einen Manipulator aufgerufen, |
| (const ideeString &name) | um den aktuellen Attributnamen zu setzen. |
| statAsciiDb& startDocument | Wird über einen Manipulator aufgerufen, |
| (const ideeString &name) | um den aktuellen Dokumentennamen zu setzen. |
| statAsciiDb& endDocument | Wird über einen Manipulator aufgerufen, |
| (const ideeString &name) | um den aktuellen Dokumentennamen zu löschen. |
| statAsciiDb& startPage | Wird über einen Manipulator aufgerufen, |
| (const ideeString &name) | um den aktuellen Seitennamen zu setzen. |
| statAsciiDb& endPage | Wird über einen Manipulator aufgerufen, |
| (const ideeString &name) | um den aktuellen Seitennamen zu löschen. |
| statAsciiDb& startRoi | Wird über einen Manipulator aufgerufen, |
| (const ideeString &name) | um den aktuellen Roinamen zu setzen. |
| statAsciiDb& endRoi | Wird über einen Manipulator aufgerufen, |
| (const ideeString &name) | um den aktuellen Roinamen zu löschen. |
| ideeString key() const | Erzeugt den Schlüssel für ein Attribut. |
| statNode* getNode() const | Sucht den zum aktuellen Objekt gehörigenden |
| Knoten im Objektbaum. | |
| Name | Beschreibung |
| void readFile() | Liest die gesamte Datei zeilenweise |
| übergibt parseLine den Inhalt der Zeile. | |
| void parseLine | Interpretiert die Zeile und |
| (const ideeString &line) | fügt die Informationen in den Objektbaum ein. |
| Name | Beschreibung |
| void cancel() | Setzt das Attribut Aborted auf true |
| und wird durch ein Qt-Signal (Knopfdruck) aufgerufen. | |
| Name | Datentyp | Beschreibung | Zugriff |
| String | ideeString | Die vom Manipulator übergebene Zeichenkette. | |
| Func | statManipFunc | Zeiger auf Manipulator-Funktion. | |
| Name | Beschreibung |
| manip(statManipFunc func, | Der Konstruktor |
| const ideeString& string) | |
Diese Klasse erlaubt es die Resultate in eine Textdatei zu schreiben. Dabei werden die Spalten einer Zeilen durch Tabulator getrennt, so dass die Textdateien in eine Tabellenkalkulation wie Excel importiert werden können.
| Name | Datentyp | Beschreibung | Zugriff |
| Path | ideePath | Der Pfad zur Datei, | r |
| in die geschrieben werden soll. | |||
| Results | ideeStringField | Die Resultate, die geschrieben werden. | |
| Die Tabelle ist zeilenweise angeordnet. | |||
| Captions | ideeStringVec | Die Spaltenüberschriften, die in die erste | |
| Zeile der Datei gechrieben werden. | |||
| Stream | ofstream | Der Dateiausgabestream, | |
| der zum Schreiben benutzt wird. | |||
| Name | Beschreibung |
| statSpreadSheetExport | Der Konstruktor. |
| (const ideePath &path, | |
| const ideeStringVec &captions, | |
| const ideeStringField &results) | |
| Der Destruktor | |
| Name | Beschreibung |
| void open() | Öffnet die Datei und schreibt die Daten |
| throw (ideeFileOpenError) | in die Datei. Die Spalten werden durch |
| Tabulatoren getrennt. Anschliessend wird | |
| die Datei wieder geschlossen. | |
| void close() | Schliesst die Datei. |
| throw (ideeFileCloseError) | |
Diese Klasse repäsentiert die Knoteninformationen in dem Baum, der zum Wiedereinlesen der Ground-Truth benötigt wird.
| Name | Datentyp | Beschreibung | Zugriff |
| Attribs | ideeStringPairList | Liste der Attribut-Werte-Paare | r |
| Name | Beschreibung |
| statNodeObj() | Der Standardkonstruktor. |
| void addAttribute | Füge der Liste von Attributen |
| (const ideeString &name, | ein neues hinzu. |
| const ideeString &value) | |
| const ideeString &getAttribute | Sucht das erste Vorkommen |
| (const ideeString &name) const | eines Attributes mit den Namen name. |
| const ideeStringList &getAttributes | Sucht die Vorkommen von |
| (const ideeString &name) const | Attributen mit den Namen name. |
Instantiierung und Ableitung der Schablone ideeTree<T> mit statNodeObj als Parameter.
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statObjTree() | Der Standardkonstruktor. |
| void addDocument | Füge eine neues Dokument in den |
| (const ideeString &name) | Objektbaum ein. |
| Name | Datentyp | Beschreibung | Zugriff |
| TableRoi | statTableRoiPtr | Zeiger auf eine eventuell in dem | |
| Dokument enthaltene Tabelle | |||
| GT | bool | Flag, ob es sich bei den extrahierten Daten, | r |
| um Ground-Truth oder nicht handelt. Setzt | |||
| das Attribut isGT in statIfcObject. | |||
| LocalDir | ideePath | Der Pfad zu den lokal gespeicherten Pakete, | |
| die bearbeitet werden sollen. | |||
| Name | Beschreibung |
| statExtraction(bool isGT, | Der Konstruktor. |
| ideePath localPath | |
| = ideePath(''i:
|
|
| statDocumentList& extract | Extrahiert die Dokumente eines Bildstapels. |
| (dbiControlDbInterface:: | |
| ImageStackId &stackId) | |
| statDocumentListMap& extract( | Extrahiert die Bildstapel, die vom |
| bool local = false | Benutzer ausgewählt wurden. |
| Name | Beschreibung |
| void extractDoc( | Extrahiert die Daten eines |
| const ifcDocument &doc, | Dokuments und fügt ein |
| statDocumentList *dlist) | statDocument zu dlist hinzu. |
| void extractPages( | Extrahiert die Daten der |
| const ifcDocument &doc, | Seiten und fügt sie |
| statDocumentPtr &sDoc) | zu sDoc hinzu. |
| void extractRois( | Extrahiert die Daten von Feldern |
| const ifcDocument &doc, | und fügt die statRois zu sDoc hinzu. |
| statDocumentPtr &sDoc) | |
| void fillInSimpleRoi( | Füllt die eine SimpleRoi betreffende |
| ifcRoiShd &roi, | Informationen aus roi in sRoi ein. |
| statSimpleRoi *sRoi) | |
| void fillInMetaRoi( | Füllt die eine MetaRoi betreffende |
| ifcRoiShd &roi, | Informationen aus roi in sRoi ein. |
| statMetaRoi *sRoi) | |
| void extractTableCells( | Extrahiert die Tabellenzellen einer Seite |
| const ifcDocument &doc, | und füllt sie in sDoc bzw. sPage ein. |
| statDocumentPtr &sDoc, | Dabei ist zu beachten, dass es derzeit |
| ifcPageShd &page, | pro Dokument nur eine Tabelle |
| statPagePtr &sPage) | geben kann. |
| Name | Beschreibung |
| void stacksParsed( | Teilt mit, dass nrStacks Bildstapel |
| unsigned int nrStacks, | von insgesamt totalStacks Bildstapel |
| unsigned int totalStacks) | schon bearbeitet wurden. |
| void docsParsed( | Teilt mit, dass nrDocs Dokumente |
| unsigned int nrDocs, | von insgesamt totalDocss Dokumente |
| unsigned int totalDocs) | eines Bildstapels schon bearbeitet wurden. |
| Name | Datentyp | Beschreibung | Zugriff |
| Keine Attribute | |||
| Name | Beschreibung |
| statCompare | Der Konstruktor. |
| (const statDocumentPtr &doc, | |
| const statDocumentPtr >) | |
This document was generated using the LaTeX2HTML translator Version 99.2beta8 (1.43)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -no_subdir -split 0 -show_section_numbers /tmp/lyx_tmpdir859hQfn71/lyx_tmpbuf859ArhFQ1/benchmark.tex
The translation was initiated by Jochen Schäfer on 2002-05-27